Add detailed articles on MVCC, MySQL logging mechanisms, and locking strategies
- Created a comprehensive article on MVCC (Multi-Version Concurrency Control) explaining its principles, challenges in concurrency control, and the mechanisms of current reads and snapshot reads. - Added an in-depth exploration of MySQL's binlog, redolog, and undolog, detailing their purposes, differences, and roles in data recovery and transaction management. - Developed a thorough guide on MySQL's locking mechanisms, including global locks, table-level locks, and row-level locks, with explanations of intent locks, auto-increment locks, and the implications of each locking strategy on concurrency and data integrity.
This commit is contained in:
105
src/content/posts/中间件/MySQL/MVCC.md
Normal file
105
src/content/posts/中间件/MySQL/MVCC.md
Normal file
@@ -0,0 +1,105 @@
|
||||
---
|
||||
title: MVCC-多版本并发控制
|
||||
published: 2025-08-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MVCC]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||
# MVCC
|
||||
MVCC,也就是多版本并发控制
|
||||
|
||||
它的目的是: 提高数据库并发性能,用更好的方式处理读写冲突,也就是即使有读写冲突的时候,也能做到不加锁。
|
||||
|
||||
|
||||
## 并发控制的挑战
|
||||
在数据库系统中,同时执行的事务可能涉及相同的数据,因此需要一种机制来保证数据的一致性,传统的锁机制可以实现并发控制,但会导致阻塞和死锁等问题。
|
||||
|
||||
## 传统锁机制
|
||||
|
||||
|
||||
## 当前读和快照读
|
||||
|
||||
### 当前读
|
||||
在MySQL中,当前读是一种读取数据的操作方式,它可以直接读取最新的数据版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁,MySQL提供了两种实现当前读的机制:
|
||||
|
||||
- 锁定读:
|
||||
- 锁定读是一种特殊情况下的当前读方式,在某些场景下使用
|
||||
- 在使用锁定读的时候,MySQL会在执行读取操作前获取共享锁或者排他锁,确保数据一致性。
|
||||
- 共享锁允许多个事务读取统一数据,而排他锁组织其他事务读取或者写入该数据。
|
||||
- 锁定读适用于需要严格控制并发访问的场景,但是由于加锁带来的性能开销较大,所以只在必要的时候才使用。
|
||||
|
||||

|
||||
|
||||
|
||||

|
||||
|
||||
这种就属于悲观锁实现。
|
||||
|
||||
### 快照读
|
||||
快照读就是在读取数据的时候,读取一个一致性视图中的数据,MySQL通过MVCC机制来支持快照读。
|
||||
|
||||
具体而言,每个食物在开始的时候都会创建一个一致性视图,这个一致性视图会记录当前事务开始时已经提交的数据版本。
|
||||
|
||||
执行查询的时候,MySQL会根据事务的一致性视图来决定可见的数据版本。只有那些在事务开始之前就已经提交的数据版本才是可见的,未提交或在事务开始后修改的数据则对当前事务不可见。
|
||||
|
||||
像不加锁的select操作就是快照读,也就是不加锁的非阻塞读。
|
||||
|
||||
|
||||
- 一致性读:
|
||||
- 默认隔离级别下(可重复读),MySQL使用一致性来实现当前读
|
||||
- 在事务开始的时候,MySQL会创建一个一致性视图,这个视图反映了事务开始时刻的数据库快照。
|
||||
- 在事务执行期间,无论其他事务对数据进行了何种修改,事务始终使用一致性视图来读取数据。
|
||||
- 可以保证在同一事务内多次查询返回的结果是一致的.
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
快照读的前提是隔离级别不是串行级别,在串行级别下,事务之间完全串行执行,快照读会退化为当前读中的加锁读。
|
||||
|
||||
MVCC主要就是为了实现读-写冲突不加锁,这个读就是指的快照读,是乐观锁的实现。
|
||||
|
||||
|
||||
# 事务的mvcc机制原理是什么?
|
||||
MVCC允许多个事务同时读取同一行数据,而不会彼此阻塞,每个事务看到的数据版本是该事务开始时候的数据版本,这意味着,如果其他事务在此期间修改了数据,正在运行的事务仍然看到的是它开始时候的数据状态,从而实现了非阻塞读操作。
|
||||
|
||||
|
||||
对于 `读已提交` 和 `可重复读` 隔离级别的事务来说,它们是通过ReadView来实现的,它们的区别在于创建ReadView的时机不同。
|
||||
ReadView可以理解为当时的一个快照视图,它记录了在创建时刻可见的数据版本。
|
||||
|
||||
|
||||
读提交隔离级别: 在每个select语句执行前,都会重新生成一个ReadView。每个SELECT生成新的ReadView
|
||||
只能读到其他事务已提交的版本
|
||||
不能读到未提交事务的修改
|
||||
这保证了不会出现"脏读"
|
||||
但会出现"不可重复读"
|
||||
|
||||
可重复读隔离级别: 在事务中,执行第一条select语句的时候,生成一个ReadView,然后整个事务期间都在使用这个ReadView
|
||||
|
||||
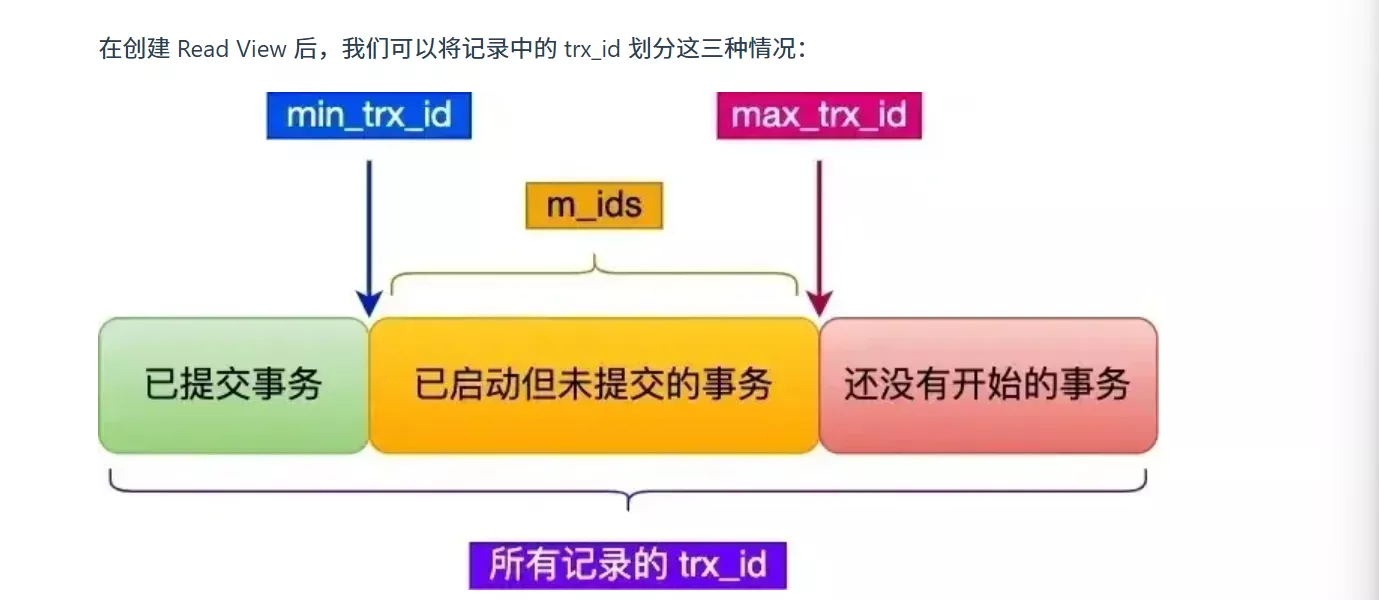
ReadView有四个重要字段:
|
||||
- creator_trx_id 创建该Read View的事务的事务id
|
||||
- m_ids 创建ReadView的时候,当前数据库中活跃且未提交的事务id列表,所谓活跃事务,指的就是启动了但是还没提交的事务
|
||||
- min_trx_id 创建ReadView的时候当前数据库中活跃且未提交的事务中最小的事务的事务id
|
||||
- max_trx_id 创建ReadView的时候,当前数据库中应该给下一个事务的id值,也就是全局事务中最大的事务id + 1
|
||||
|
||||
对于使用InnoDB存储引擎的数据库表,它的聚簇索引记录中都包含下面两个隐藏列
|
||||
- trx_id 记录最后修改该行数据的事务的事务id
|
||||
- roll_pointer 记录该行数据的回滚指针,用于实现MVCC(也就是undo日志)
|
||||
|
||||
每次对某条聚簇索引记录进行改动的时候,都会把旧版本的记录写入到undo日志中,然后这个隐藏列是个指针,指向每个旧版本记录,于是就可以通过它找到修改前的记录。
|
||||
|
||||
|
||||
|
||||
一个事务去访问记录的时候,除了自己的更新记录总是可见之外,还有这几种情况:
|
||||
|
||||
如果记录的 trx_id 值小于 Read View 中的 min_trx_id 值,表示这个版本的记录是在创建 Read View 前已经提交的事务生成的,所以该版本的记录对当前事务可见。
|
||||
如果记录的 trx_id 值大于等于 Read View 中的 max_trx_id 值,表示这个版本的记录是在创建 Read View 后才启动的事务生成的,所以该版本的记录对当前事务不可见。
|
||||
如果记录的 trx_id 值在 Read View 的 min_trx_id 和 max_trx_id 之间,需要判断 trx_id 是否在 m_ids 列表中:
|
||||
如果记录的 trx_id 在 m_ids 列表中,表示生成该版本记录的活跃事务依然活跃着(还没提交事务),所以该版本的记录对当前事务不可见。
|
||||
如果记录的 trx_id 不在 m_ids列表中,表示生成该版本记录的活跃事务已经被提交,所以该版本的记录对当前事务可见。
|
||||
这种通过「版本链」来控制并发事务访问同一个记录时的行为就叫 MVCC(多版本并发控制)。
|
||||
42
src/content/posts/中间件/MySQL/MySQLbinlog,redolog和undolog.md
Normal file
42
src/content/posts/中间件/MySQL/MySQLbinlog,redolog和undolog.md
Normal file
@@ -0,0 +1,42 @@
|
||||
---
|
||||
title: MySQLbinlog,redolog和undolog
|
||||
published: 2025-08-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: [MySQL, binlog, redolog, undolog]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# MySQL的binlog、redolog和undolog详解
|
||||

|
||||
|
||||
## binlog
|
||||
binlog
|
||||
用途:
|
||||
1. 主从复制
|
||||
2. 数据恢复
|
||||
3. 审计
|
||||
|
||||
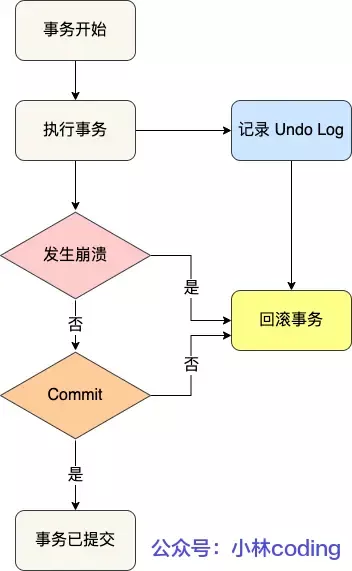
## redolog(保证持久性)
|
||||
redo log
|
||||
目的: 确保事务的持久性
|
||||
作用: 记录了数据被修改之后的值。当事务提交以后,即使数据还没有完全写入磁盘,只要redo log已经落盘,数据库在发生宕机等意外情况之后,仍然可以通过redo log来'重做'这些修改,从而恢复到宕机前的最新状态,保证了已提交事务的数据不可丢失,这是一种前滚操作。
|
||||
|
||||
|
||||
## undolog(保证原子性)
|
||||
|
||||
目的: 保证事务的原子性和实现多版本并发控制。
|
||||
作用: 记录的是数据被修改之前的旧版本。当一个事务需要回滚的时候,数据库可以利用undo log中的信息将数据恢复到事务开始前的状态。
|
||||
|
||||

|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
# 区别
|
||||

|
||||
|
||||

|
||||
201
src/content/posts/中间件/MySQL/MySQL中的全局锁表级锁行级锁机制.md
Normal file
201
src/content/posts/中间件/MySQL/MySQL中的全局锁表级锁行级锁机制.md
Normal file
@@ -0,0 +1,201 @@
|
||||
---
|
||||
title: MySQL全局锁,表级锁,行级锁
|
||||
published: 2025-08-09
|
||||
description: 'MySQL中的全局锁,表级锁,行级锁机制'
|
||||
image: ''
|
||||
tags: [全局锁,表级锁,行级锁]
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
# MySQL的锁
|
||||
## 全局锁
|
||||
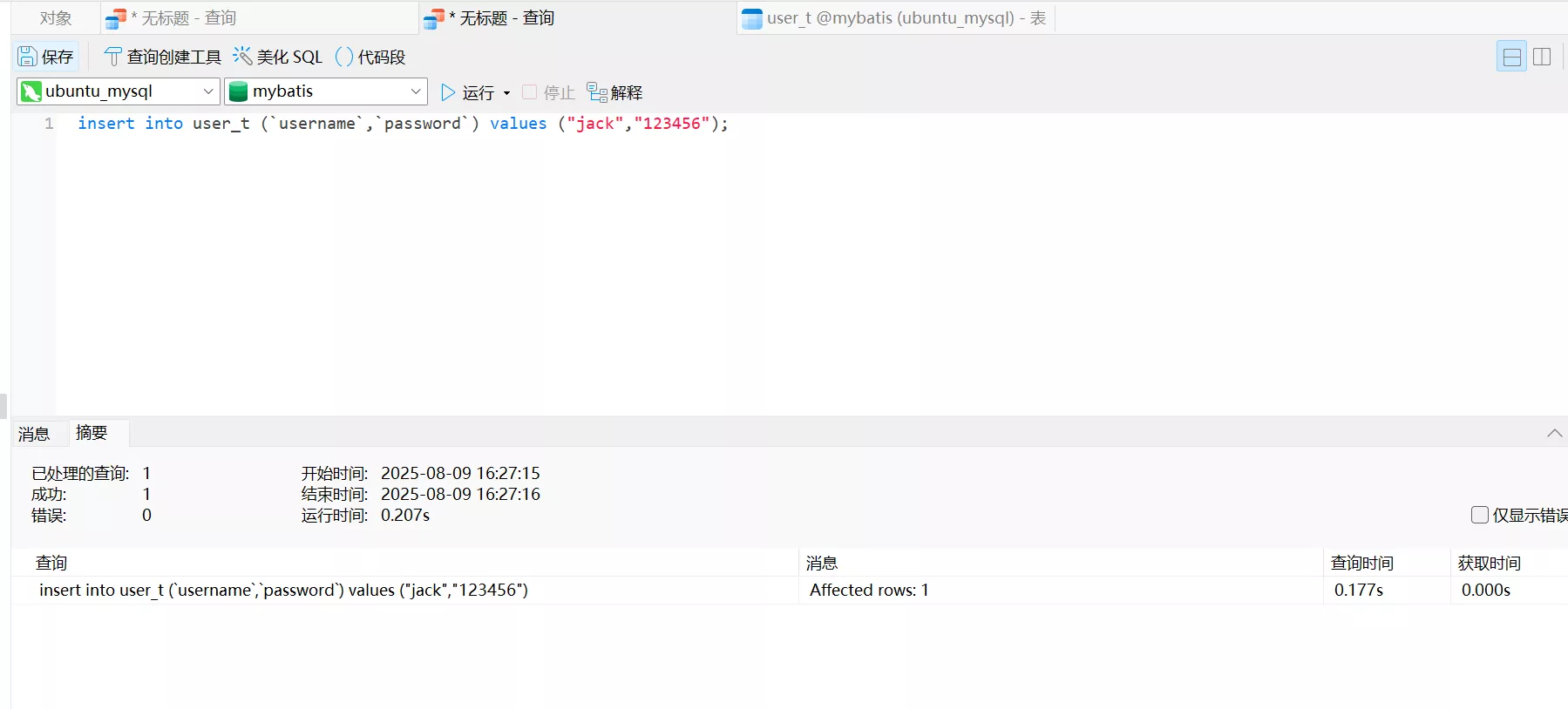
如果要使用全局锁
|
||||
要执行下面的命令:
|
||||
```sql
|
||||
flush table with read lock
|
||||
```
|
||||
|
||||
|
||||
|
||||
执行全局锁以后,数据库就变成只读状态了,插入和更新操作都会被阻塞
|
||||
|
||||
这个全局锁一般是用于数据库全局备份的。在备份数据库期间,不会因为数据和表结构的更新,出现备份文件的数据和预期的不一样。
|
||||
|
||||
|
||||
|
||||
可以看到会卡主
|
||||
|
||||
|
||||
|
||||
解锁以后就可以插入了
|
||||
|
||||
备份数据库的时候又不想停机,可以在用 mysqldump的时候加上 --single-transaction参数,就会在备份数据之前先开启事务。这种方法只适用于支持可重复读隔离级别的事务的存储引擎。
|
||||
|
||||
|
||||
## 表级锁
|
||||
MySQL中的表级锁有哪些?
|
||||
- 表锁
|
||||
- 元数据锁
|
||||
- 意向锁
|
||||
- AUTO-INC锁
|
||||
|
||||
### 表锁
|
||||
如果我们相对student表加上表锁
|
||||
```sql
|
||||
-- 允许当前会话读取被锁定的表,但是会组织其他会话对这些表进行写操作
|
||||
lock table student_t read;
|
||||
|
||||
-- 表级别的独占锁,也就是写锁
|
||||
-- 允许当前会话对表进行读写操作,但会阻止其他会话对这些表进行任何操作
|
||||
lock table student_t write;
|
||||
```
|
||||
|
||||
需要注意的是,表锁除了会限制别的线程的读写外,也会限制本线程接下来的读写操作。
|
||||
|
||||
|
||||
### 元数据锁
|
||||
元数据锁不需要显示调用,因为当我们对数据库表进行操作的时候,会自动给这个表加上MDL
|
||||
|
||||
当我们对一张表进行CRUD操作的时候,加的是MDL读锁
|
||||
当我们对一张表做结构变更操作的时候,加的是MDL写锁
|
||||
|
||||
MDL是为了保证当用户对表执行CRUD操作的时候,防止其他线程对这个表结构做变更。
|
||||
|
||||
比如说,一个线程正在执行查询操作(加了MDL读锁),如果有其他线程来修改表结构,就会被阻塞,直到查询结束。
|
||||
同理,一个线程在修改表结构的时候(申请了MDL写锁),其他线程的查询操作就会被阻塞,直到说表结构变更完成
|
||||
|
||||
|
||||
### 意向锁
|
||||
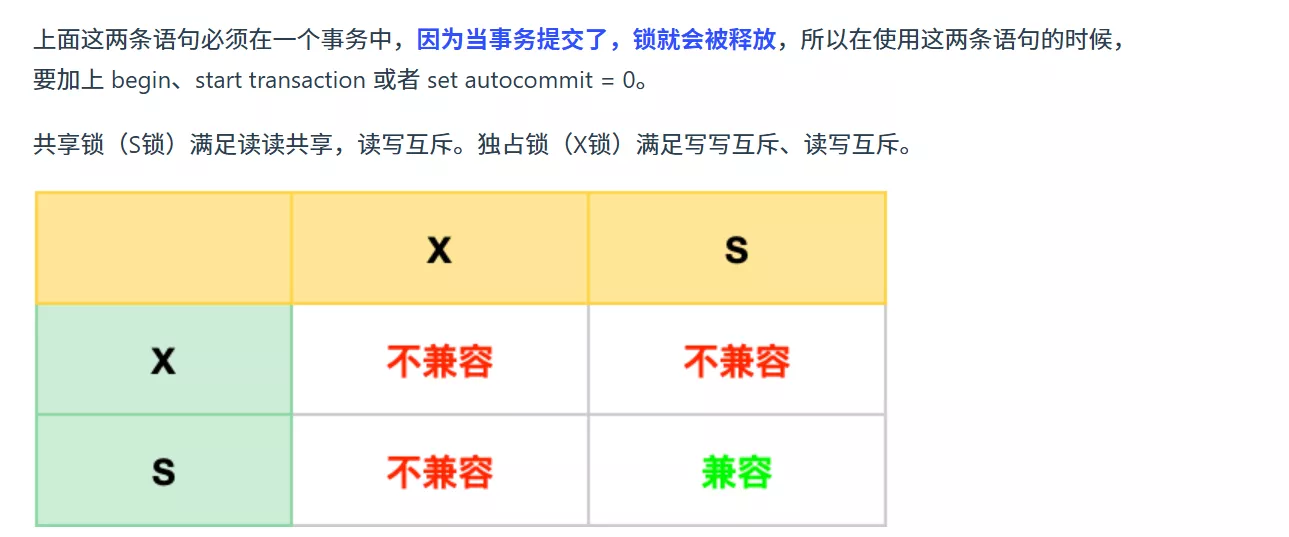
- 在使用InnoDB引擎的表里对某些记录加上共享锁之前,需要先在表级别上加一个意向共享锁。
|
||||
- 在使用InnoDB引擎的表里对某些记录加上独占锁之前,需要先在表级别加上一个意向独占锁。
|
||||
|
||||
普通的select是不会加行级锁的,因为它是用MVCC(多版本并发控制)实现的,是无锁的。
|
||||
|
||||
不过select也是可以对记录加共享锁和独占锁的。
|
||||
|
||||
```sql
|
||||
//先在表上加上意向共享锁,然后对读取的记录加共享锁
|
||||
select ... lock in share mode;
|
||||
|
||||
//先表上加上意向独占锁,然后对读取的记录加独占锁
|
||||
select ... for update;
|
||||
```
|
||||
|
||||
|
||||
> 意向共享锁和意向独占锁是表级锁,不会和行级的共享锁和独占锁发生冲突,而且意向锁之间也不会发生冲突,只会和共享表锁和独占锁发生冲突。
|
||||
|
||||
意向锁的目的是为了快速判断表里是否有记录被加锁。
|
||||
比如说,当一个事务想要对某个记录加锁时,可以先检查表级的意向锁,如果表级的意向锁是共享锁,就说明有其他事务正在读取这个表中的记录;如果是独占锁,就说明有其他事务正在修改这个表中的记录。
|
||||
|
||||
如果表级的意向锁是共享锁,那么其他事务可以对表上共享锁,但是不能加独占锁。如果是表级意向锁是独占锁,其他事务就不能对表上加任何锁。
|
||||
|
||||
|
||||
### AUTO-INC锁
|
||||
表里的主键通常会设置成自增的,这是通过主键字段声明 AUTO_INCREMENT 属性实现的。
|
||||
|
||||
之后可以在插入数据的时候,可以不指定主键的值,数据库会自动给主键赋值递增的值,这主要是通过 AUTO-INC锁实现的。
|
||||
|
||||
AUTO-INC锁是特殊的表锁机制,锁不是在一个事务提交后才释放,而是在执行完插入语句后就会立刻释放。
|
||||
|
||||
在插入数据的时候,会加一个表级别的AUTO-INC锁,然后为被 `AUTO_INCREMENT` 修饰的字段赋值递增的值,等插入语句执行完成后,才会把AUTO-INC锁释放掉。
|
||||
|
||||
那么在一个事务持有AUTO-INC锁的过程中,其他事务如果要向该表插入语句都会被阻塞,从而保证了插入数据的时候,被AUTO_INCREMENT修饰的字段的值是连续递增的。
|
||||
|
||||
因此,在MySQL5.1.22开始,InnoDB存储引擎提供了一种轻量级的锁来实现自增。
|
||||
|
||||
一样也是在插入数据的时候,会为被auto_increment修饰的字段加上轻量级锁,然后给该字段赋值一个自增的值,然后就把这个轻量级锁释放了,不需要等待整个插入语句执行完成后才释放锁。
|
||||
|
||||
## 行级锁
|
||||
InnoDB引擎是支持行级锁的,而MyISAM不支持行级锁
|
||||
|
||||
可以使用下面这两个方式,这种查询会加锁的语句称为锁定读。
|
||||
```sql
|
||||
//对读取的记录加共享锁
|
||||
select ... lock in share mode;
|
||||
|
||||
//对读取的记录加独占锁
|
||||
select ... for update;
|
||||
```
|
||||
|
||||
|
||||
|
||||
### 行级锁类型
|
||||
有三类:
|
||||
- Record Lock,记录锁,也就是仅仅把一条记录锁上
|
||||
- Gap Lock 间隙锁,锁定一个范围,但是不包含记录本身
|
||||
- Next-Key Lock: Record Lock + Gap Lock的组合,锁定一个范围,并且锁定记录本身
|
||||
|
||||
|
||||
### Record Lock 记录锁
|
||||
Record Lock被称为记录锁,锁住的锁一条记录,而且记录锁是有S锁和X锁之分的。
|
||||
|
||||
- 当一个事务对一条记录加了S型记录锁后,其他事务也可以继续对该记录加S型记录锁,但是不可以对该记录加X型记录锁
|
||||
- 当一个事务对一条记录加了X型记录锁后,其他事务不可以对该记录加S型记录锁,也不可对该记录加X型记录锁
|
||||
|
||||
|
||||

|
||||
|
||||
### Gap Lock 间隙锁
|
||||
|
||||
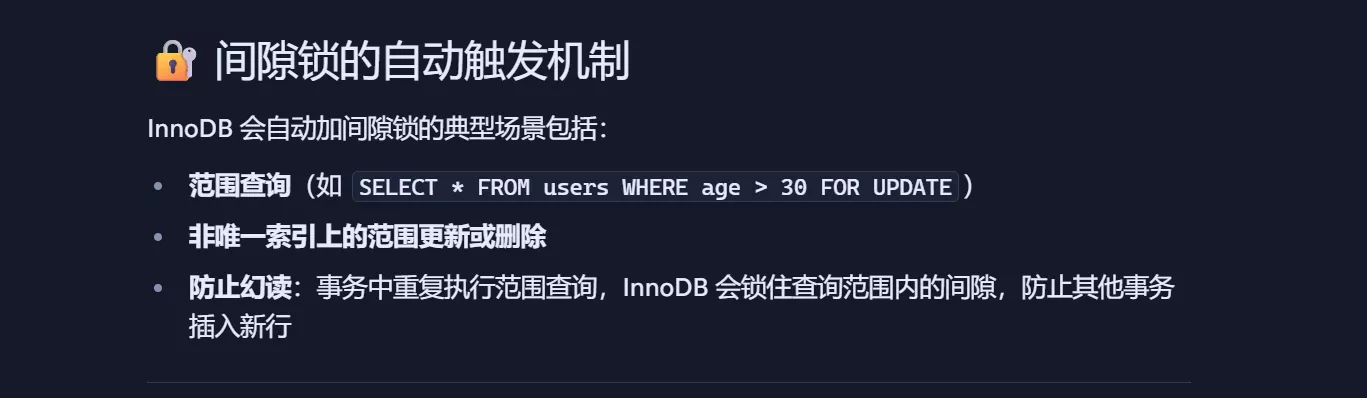
Gap Lock被称为间隙锁,存在于可重复读隔离级别和串行化隔离级别,目的是为了解决可重复读隔离级别下幻读的现象
|
||||
|
||||
|
||||
假设表中有一个范围id为(3,5)的间隙锁,那么其他事务就无法插入id = 4这条记录了,这样就有效地防止了幻读现象的发生。
|
||||
|
||||
间隙锁虽然也存在X型和S型间隙锁,但是没什么区别,间隙锁之间是兼容的,两个事务可以同时持有并包含共同间隙范围的间隙锁,并不存在互斥关系,因为间隙锁的目的是防止插入幻影记录而提出的。
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||

|
||||
|
||||
|
||||
### Next-Key Lock 临键锁
|
||||
|
||||
Next-Key-Lock称为临键锁,是Record Lock和Gap Lock的组合。锁定一个范围,并且锁定记录本身。
|
||||
假设表中有个范围id为(3,5]的next-key-lock,那么其它事务既不能插入id = 4的记录,也不能修改id = 5这条记录。
|
||||
|
||||
所以next-key lock既能保护该记录,又能阻止其它事务将新记录插入到被保护记录前面的间隙中。
|
||||
|
||||
Next-key lock 是数据库中 InnoDB 存储引擎(常见于 MySQL)使用的一种锁机制,主要用于防止 **幻读(Phantom Read)** 问题,确保事务在可重复读(Repeatable Read)隔离级别下的一致性。它的意义在于通过结合 **记录锁(Record Lock)** 和 **间隙锁(Gap Lock)**,对索引记录及其前后的间隙进行锁定,从而避免其他事务插入或修改数据导致的幻读现象。
|
||||
|
||||
#### 具体意义和作用:
|
||||
1. **防止幻读**:
|
||||
- 幻读是指在同一事务中,多次执行相同查询时,由于其他事务插入了新记录,导致查询结果集发生变化。
|
||||
- Next-key lock 锁定一个索引记录及其前后的间隙,防止其他事务插入新记录到这个范围内,从而保证查询结果的稳定性。
|
||||
|
||||
2. **结合记录锁和间隙锁**:
|
||||
- **记录锁**:锁定具体的索引记录,防止其他事务修改或删除该记录。
|
||||
- **间隙锁**:锁定索引记录之间的“间隙”,防止其他事务在该间隙内插入新记录。
|
||||
- Next-key lock 是两者的结合,锁定一个记录及其左侧或右侧的间隙。例如,对于索引值 10,Next-key lock 可能锁定 (5, 10] 范围(假设 5 是前一个索引值)。
|
||||
|
||||
3. **提高并发控制的精度**:
|
||||
- Next-key lock 是一种范围锁,比表级锁更精细,能够在保证数据一致性的同时,尽量减少锁的粒度,提高并发性能。
|
||||
|
||||
4. **支持可重复读隔离级别**:
|
||||
- 在 MySQL 的可重复读(Repeatable Read)隔离级别下,Next-key lock 是默认的锁机制,用于确保事务在多次读取时看到一致的数据快照。
|
||||
|
||||
#### 工作原理:
|
||||
- 当事务对某一行记录进行操作(例如 SELECT ... FOR UPDATE 或 UPDATE),InnoDB 会锁定该记录以及其前后的间隙。
|
||||
- 例如,假设表中有一个索引列 `id` 包含值 10、20、30。如果事务 A 对 `id = 20` 加锁,Next-key lock 可能会锁定 (10, 20] 或 (20, 30] 的范围,防止其他事务插入值在该范围内的记录。
|
||||
|
||||
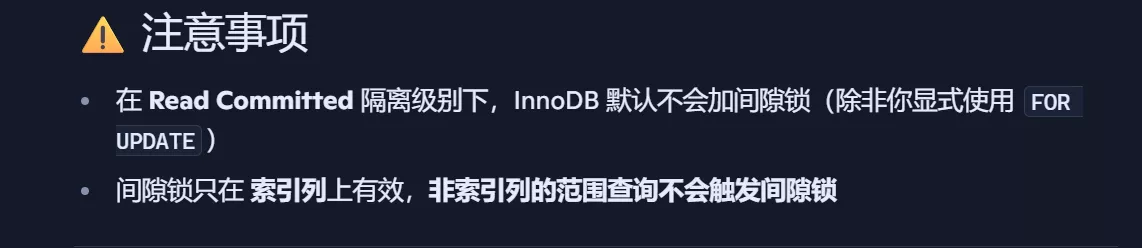
#### 注意事项:
|
||||
1. **性能影响**:Next-key lock 锁定范围较大,可能导致锁冲突,降低并发性能。
|
||||
2. **死锁风险**:多个事务竞争相同的间隙锁可能导致死锁,需要合理设计事务逻辑。
|
||||
3. **依赖索引**:Next-key lock 依赖于索引。如果查询没有使用索引,可能会退化为表级锁,影响性能。
|
||||
|
||||
总结来说,Next-key lock 的核心意义在于通过锁定记录和间隙,防止幻读,维护事务隔离级别的一致性,同时在高并发场景下提供较好的数据保护机制。
|
||||
|
||||
|
||||
### 插入意向锁
|
||||
一个事务在插入一条记录的时候,需要判断插入位置是否已被其他事务加了间隙锁(next-key lock 也包含间隙锁)。
|
||||
|
||||
如果有的话,插入操作就会发生阻塞,直到拥有间隙锁的那个事务提交为止(释放间隙锁的时刻),在此期间会生成一个插入意向锁,表明有事务想在某个区间插入新记录,但是现在处于等待状态。
|
||||
@@ -16,6 +16,7 @@ C : Consistency(一致性)
|
||||
I : Isolation(隔离性)
|
||||
D : Durability(持久性)
|
||||
|
||||

|
||||
|
||||
# Atomicity(原子性)
|
||||
这里要先讲一下什么是事务: 简单说,事务就是一组原子性的SQL执行单元。如果数据库引擎能够成功地对数据库应 用该组査询的全部语句,那么就执行该组SQL。如果其中有任何一条语句因为崩溃或其 他原因无法执行,那么所有的语句都不会执行。要么全部执行成功(commit),要么全部执行失败(rollback)。
|
||||
|
||||
Reference in New Issue
Block a user