feat: 新增子分类功能,美化profile
This commit is contained in:
@@ -4,6 +4,7 @@ import { onMount } from "svelte";
|
|||||||
import I18nKey from "../i18n/i18nKey";
|
import I18nKey from "../i18n/i18nKey";
|
||||||
import { i18n } from "../i18n/translation";
|
import { i18n } from "../i18n/translation";
|
||||||
import { getPostUrlBySlug } from "../utils/url-utils";
|
import { getPostUrlBySlug } from "../utils/url-utils";
|
||||||
|
import { getCategoryAncestors } from "../utils/url-utils";
|
||||||
|
|
||||||
export let tags: string[];
|
export let tags: string[];
|
||||||
export let categories: string[];
|
export let categories: string[];
|
||||||
@@ -53,9 +54,24 @@ onMount(async () => {
|
|||||||
}
|
}
|
||||||
|
|
||||||
if (categories.length > 0) {
|
if (categories.length > 0) {
|
||||||
filteredPosts = filteredPosts.filter(
|
filteredPosts = filteredPosts.filter((post) => {
|
||||||
(post) => post.data.category && categories.includes(post.data.category),
|
if (!post.data.category) return false;
|
||||||
);
|
|
||||||
|
// 简单的字符串匹配,支持层级匹配
|
||||||
|
return categories.some(filterCategory => {
|
||||||
|
// 直接匹配
|
||||||
|
if (post.data.category === filterCategory) {
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
// 如果文章分类以 "filterCategory > " 开头,说明是子分类
|
||||||
|
if (post.data.category.startsWith(filterCategory + ' > ')) {
|
||||||
|
return true;
|
||||||
|
}
|
||||||
|
|
||||||
|
return false;
|
||||||
|
});
|
||||||
|
});
|
||||||
}
|
}
|
||||||
|
|
||||||
if (uncategorized) {
|
if (uncategorized) {
|
||||||
|
|||||||
79
src/components/widget/HierarchicalCategories.astro
Normal file
79
src/components/widget/HierarchicalCategories.astro
Normal file
@@ -0,0 +1,79 @@
|
|||||||
|
---
|
||||||
|
import I18nKey from "../../i18n/i18nKey";
|
||||||
|
import { i18n } from "../../i18n/translation";
|
||||||
|
import { getCategoryList } from "../../utils/content-utils";
|
||||||
|
import type { Category } from "../../utils/content-utils";
|
||||||
|
import ButtonLink from "../control/ButtonLink.astro";
|
||||||
|
import WidgetLayout from "./WidgetLayout.astro";
|
||||||
|
|
||||||
|
const categories = await getCategoryList();
|
||||||
|
|
||||||
|
const COLLAPSED_HEIGHT = "12rem";
|
||||||
|
const COLLAPSE_THRESHOLD = 5;
|
||||||
|
|
||||||
|
const isCollapsed = categories.length >= COLLAPSE_THRESHOLD;
|
||||||
|
|
||||||
|
interface Props {
|
||||||
|
class?: string;
|
||||||
|
style?: string;
|
||||||
|
}
|
||||||
|
const className = Astro.props.class;
|
||||||
|
const style = Astro.props.style;
|
||||||
|
|
||||||
|
// 扁平化分类树以便显示
|
||||||
|
function flattenCategories(categories: Category[], level: number = 0): Array<Category & { displayLevel: number }> {
|
||||||
|
const result: Array<Category & { displayLevel: number }> = [];
|
||||||
|
|
||||||
|
for (const category of categories) {
|
||||||
|
result.push({ ...category, displayLevel: level });
|
||||||
|
if (category.children.length > 0) {
|
||||||
|
result.push(...flattenCategories(category.children, level + 1));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
return result;
|
||||||
|
}
|
||||||
|
|
||||||
|
const flatCategories = flattenCategories(categories);
|
||||||
|
---
|
||||||
|
|
||||||
|
<WidgetLayout
|
||||||
|
name={i18n(I18nKey.categories)}
|
||||||
|
id="hierarchical-categories"
|
||||||
|
isCollapsed={isCollapsed}
|
||||||
|
collapsedHeight={COLLAPSED_HEIGHT}
|
||||||
|
class={className}
|
||||||
|
style={style}
|
||||||
|
>
|
||||||
|
{flatCategories.map((category) => (
|
||||||
|
<div class={`category-item level-${category.displayLevel}`} style={`margin-left: ${category.displayLevel * 1}rem`}>
|
||||||
|
<ButtonLink
|
||||||
|
url={category.url}
|
||||||
|
badge={String(category.count)}
|
||||||
|
label={`View all posts in the ${category.fullName} category`}
|
||||||
|
>
|
||||||
|
{category.displayLevel > 0 ? `└ ${category.name}` : category.name}
|
||||||
|
</ButtonLink>
|
||||||
|
</div>
|
||||||
|
))}
|
||||||
|
</WidgetLayout>
|
||||||
|
|
||||||
|
<style>
|
||||||
|
.category-item {
|
||||||
|
margin-bottom: 0.25rem;
|
||||||
|
}
|
||||||
|
|
||||||
|
.level-0 {
|
||||||
|
font-weight: 600;
|
||||||
|
}
|
||||||
|
|
||||||
|
.level-1 {
|
||||||
|
font-size: 0.9rem;
|
||||||
|
opacity: 0.9;
|
||||||
|
}
|
||||||
|
|
||||||
|
.level-2 {
|
||||||
|
font-size: 0.85rem;
|
||||||
|
opacity: 0.8;
|
||||||
|
}
|
||||||
|
</style>
|
||||||
@@ -7,17 +7,25 @@ import ImageWrapper from "../misc/ImageWrapper.astro";
|
|||||||
const config = profileConfig;
|
const config = profileConfig;
|
||||||
---
|
---
|
||||||
<div class="card-base p-3">
|
<div class="card-base p-3">
|
||||||
<a aria-label="Go to About Page" href={url('/about/')}
|
<div class="flex justify-center">
|
||||||
class="group block relative mx-auto mt-1 lg:mx-0 lg:mt-0 mb-3
|
<a aria-label="Go to About Page" href={url('/about/')}
|
||||||
max-w-[12rem] lg:max-w-none overflow-hidden rounded-xl active:scale-95">
|
class="group block relative w-32 h-32 lg:w-40 lg:h-40 overflow-hidden rounded-full active:scale-95 mb-3">
|
||||||
<div class="absolute transition pointer-events-none group-hover:bg-black/30 group-active:bg-black/50
|
|
||||||
w-full h-full z-50 flex items-center justify-center">
|
<!-- 彩虹旋转边框 -->
|
||||||
<Icon name="fa6-regular:address-card"
|
<div class="rainbow-border"></div>
|
||||||
class="transition opacity-0 scale-90 group-hover:scale-100 group-hover:opacity-100 text-white text-5xl">
|
|
||||||
</Icon>
|
<!-- 头像容器,确保在彩虹之上 -->
|
||||||
</div>
|
<div class="relative z-10 bg-[var(--card-bg)] rounded-full m-1 group-hover:m-2 transition-all w-[calc(100%-8px)] h-[calc(100%-8px)] overflow-hidden">
|
||||||
<ImageWrapper src={config.avatar || ""} alt="Profile Image of the Author" class="mx-auto lg:w-full h-full lg:mt-0 "></ImageWrapper>
|
<div class="absolute transition pointer-events-none group-hover:bg-black/30 group-active:bg-black/50
|
||||||
</a>
|
w-full h-full z-20 flex items-center justify-center rounded-full">
|
||||||
|
<Icon name="fa6-regular:address-card"
|
||||||
|
class="transition opacity-0 scale-90 group-hover:scale-100 group-hover:opacity-100 text-white text-3xl">
|
||||||
|
</Icon>
|
||||||
|
</div>
|
||||||
|
<ImageWrapper src={config.avatar || ""} alt="Profile Image of the Author" class="w-full h-full object-cover rounded-full"></ImageWrapper>
|
||||||
|
</div>
|
||||||
|
</a>
|
||||||
|
</div>
|
||||||
<div class="px-2">
|
<div class="px-2">
|
||||||
<div class="font-bold text-xl text-center mb-1 dark:text-neutral-50 transition">{config.name}</div>
|
<div class="font-bold text-xl text-center mb-1 dark:text-neutral-50 transition">{config.name}</div>
|
||||||
<div class="h-1 w-5 bg-[var(--primary)] mx-auto rounded-full mb-2 transition"></div>
|
<div class="h-1 w-5 bg-[var(--primary)] mx-auto rounded-full mb-2 transition"></div>
|
||||||
@@ -37,3 +45,64 @@ const config = profileConfig;
|
|||||||
</div>
|
</div>
|
||||||
</div>
|
</div>
|
||||||
|
|
||||||
|
<style>
|
||||||
|
.rainbow-border {
|
||||||
|
position: absolute;
|
||||||
|
top: -3px;
|
||||||
|
left: -3px;
|
||||||
|
right: -3px;
|
||||||
|
bottom: -3px;
|
||||||
|
background: conic-gradient(
|
||||||
|
from 0deg,
|
||||||
|
#ff0000 0deg,
|
||||||
|
#ff4500 45deg,
|
||||||
|
#ffa500 90deg,
|
||||||
|
#ffff00 135deg,
|
||||||
|
#9aff9a 180deg,
|
||||||
|
#00ff00 225deg,
|
||||||
|
#00ffff 270deg,
|
||||||
|
#0080ff 315deg,
|
||||||
|
#4169e1 360deg,
|
||||||
|
#8a2be2 405deg,
|
||||||
|
#da70d6 450deg,
|
||||||
|
#ff1493 495deg,
|
||||||
|
#ff0000 540deg
|
||||||
|
);
|
||||||
|
border-radius: 50%;
|
||||||
|
z-index: 0;
|
||||||
|
animation: rainbow-spin 4s linear infinite;
|
||||||
|
opacity: 0.8;
|
||||||
|
transition: all 0.3s ease;
|
||||||
|
filter: blur(0.5px);
|
||||||
|
}
|
||||||
|
|
||||||
|
.group:hover .rainbow-border {
|
||||||
|
opacity: 1;
|
||||||
|
animation-duration: 2s;
|
||||||
|
filter: blur(0px);
|
||||||
|
top: -5px;
|
||||||
|
left: -5px;
|
||||||
|
right: -5px;
|
||||||
|
bottom: -5px;
|
||||||
|
}
|
||||||
|
|
||||||
|
@keyframes rainbow-spin {
|
||||||
|
from {
|
||||||
|
transform: rotate(0deg);
|
||||||
|
}
|
||||||
|
to {
|
||||||
|
transform: rotate(360deg);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/* 确保圆形头像容器的比例 */
|
||||||
|
.group > div:not(.rainbow-border) {
|
||||||
|
aspect-ratio: 1;
|
||||||
|
}
|
||||||
|
|
||||||
|
.group:hover > div:not(.rainbow-border) {
|
||||||
|
width: calc(100% - 16px);
|
||||||
|
height: calc(100% - 16px);
|
||||||
|
margin: 8px;
|
||||||
|
}
|
||||||
|
</style>
|
||||||
@@ -1,6 +1,6 @@
|
|||||||
---
|
---
|
||||||
import type { MarkdownHeading } from "astro";
|
import type { MarkdownHeading } from "astro";
|
||||||
import Categories from "./Categories.astro";
|
import HierarchicalCategories from "./HierarchicalCategories.astro";
|
||||||
import Profile from "./Profile.astro";
|
import Profile from "./Profile.astro";
|
||||||
import Tag from "./Tags.astro";
|
import Tag from "./Tags.astro";
|
||||||
|
|
||||||
@@ -16,7 +16,7 @@ const className = Astro.props.class;
|
|||||||
<Profile></Profile>
|
<Profile></Profile>
|
||||||
</div>
|
</div>
|
||||||
<div id="sidebar-sticky" class="transition-all duration-700 flex flex-col w-full gap-4 top-4 sticky top-4">
|
<div id="sidebar-sticky" class="transition-all duration-700 flex flex-col w-full gap-4 top-4 sticky top-4">
|
||||||
<Categories class="onload-animation" style="animation-delay: 150ms"></Categories>
|
<HierarchicalCategories class="onload-animation" style="animation-delay: 150ms"></HierarchicalCategories>
|
||||||
<Tag class="onload-animation" style="animation-delay: 200ms"></Tag>
|
<Tag class="onload-animation" style="animation-delay: 200ms"></Tag>
|
||||||
</div>
|
</div>
|
||||||
</div>
|
</div>
|
||||||
|
|||||||
271
src/content/posts/Java/JUC/ABA问题.md
Normal file
271
src/content/posts/Java/JUC/ABA问题.md
Normal file
@@ -0,0 +1,271 @@
|
|||||||
|
---
|
||||||
|
title: ABA问题
|
||||||
|
published: 2025-07-19
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [JUC, ABA问题]
|
||||||
|
category: 'Java > JUC'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
|
||||||
|
# 介绍
|
||||||
|
|
||||||
|
ABA问题是并发编程中,在使用无锁(lock-free)算法,特别是基于 比较并交换(Compare-And-Swap, CAS) 操作时可能出现的一种逻辑错误。
|
||||||
|
|
||||||
|
它之所以被称为"ABA"问题,是因为一个变量的值从 A 变成了 B,然后又变回了 A。对于一个只检查当前值是否等于期望值的CAS操作来说,它会认为值没有发生变化,从而成功执行操作,但实际上变量在期间已经被修改过了。
|
||||||
|
|
||||||
|
## **ABA问题发生的场景及危害**
|
||||||
|
|
||||||
|
想象一个无锁的栈(Stack),其 `pop()` 操作需要原子地更新栈顶元素。
|
||||||
|
|
||||||
|
**假设初始状态:**
|
||||||
|
栈顶 `top` 指向元素 `A`。
|
||||||
|
|
||||||
|
**正常 `pop` 操作流程:**
|
||||||
|
|
||||||
|
1. 线程1读取当前栈顶元素 `A`。
|
||||||
|
2. 线程1准备将栈顶更新为 `A.next` (假设是 `null`)。
|
||||||
|
3. 线程1执行 `top.compareAndSet(A, A.next)`,如果成功,`A` 被弹出。
|
||||||
|
|
||||||
|
**ABA问题发生过程:**
|
||||||
|
|
||||||
|
1. **线程1** 读取当前栈顶元素,发现是 `A`。它记下 `A`,并准备执行 `CAS(A, C)`。
|
||||||
|
|
||||||
|
```
|
||||||
|
top -> A -> B -> D
|
||||||
|
Thread 1 reads top: A
|
||||||
|
```
|
||||||
|
|
||||||
|
2. **线程2** 此时突然执行,它将 `A` 弹出。
|
||||||
|
|
||||||
|
```
|
||||||
|
top -> B -> D (A is now removed)
|
||||||
|
Thread 2 pops A
|
||||||
|
```
|
||||||
|
|
||||||
|
3. **线程2** 又将一个**新的元素 `A` (或者一个值和 `A` 相同但实际上是不同对象的元素)**压入栈。
|
||||||
|
*注意:这里的“新的元素A”指的是一个与最开始的A值相同,但内存地址可能不同,或者即便内存地址相同,其内部状态已经发生过变化的对象。*
|
||||||
|
|
||||||
|
```
|
||||||
|
top -> A -> B -> D (This A is NOT the original A, it's a new one!)
|
||||||
|
Thread 2 pushes A back
|
||||||
|
```
|
||||||
|
|
||||||
|
4. **线程1** 恢复执行 `CAS(A, C)`。它检查当前栈顶是否是它之前读取的 `A`。
|
||||||
|
由于栈顶现在又指向了 `A`(尽管是新的 `A`),`compareAndSet` 操作会认为当前值等于期望值 `A`,并成功将栈顶更新为 `C`。
|
||||||
|
|
||||||
|
```
|
||||||
|
top -> C (Thread 1's CAS(A, C) succeeds!)
|
||||||
|
```
|
||||||
|
|
||||||
|
**危害:**
|
||||||
|
尽管线程1的CAS操作成功了,但它操作的实际上是一个**新的 `A`**,而不是它最初读取的那个 `A`。如果 `A` 的内部状态(比如它的 `next` 指针)在这期间被改变了,那么线程1的后续操作可能会导致:
|
||||||
|
|
||||||
|
* **数据结构损坏**:例如,在链表中,节点指针可能指向错误的位置。
|
||||||
|
* **逻辑错误**:程序基于过时的或不正确的状态信息做出决策。
|
||||||
|
* **内存泄漏**:旧的 `A` (或其他被弹出又压入的元素)可能永远无法被垃圾回收。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.aba;
|
||||||
|
|
||||||
|
import java.util.concurrent.atomic.AtomicReference;
|
||||||
|
|
||||||
|
class Node {
|
||||||
|
public final String item; // 节点内容
|
||||||
|
public Node next; // 下一个节点的引用
|
||||||
|
|
||||||
|
public Node(String item) {
|
||||||
|
this.item = item;
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public String toString() {
|
||||||
|
return item;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
class LockFreeStackABA {
|
||||||
|
private AtomicReference<Node> top = new AtomicReference<>();
|
||||||
|
|
||||||
|
// 压入栈顶
|
||||||
|
public void push(String item) {
|
||||||
|
Node newHead = new Node(item);
|
||||||
|
Node oldHead;
|
||||||
|
do {
|
||||||
|
oldHead = top.get();
|
||||||
|
newHead.next = oldHead;
|
||||||
|
} while (!top.compareAndSet(oldHead, newHead));
|
||||||
|
System.out.println(Thread.currentThread().getName() + " 压入: " + item + " (当前栈顶: " + top.get() + ")");
|
||||||
|
}
|
||||||
|
|
||||||
|
// 弹出栈顶
|
||||||
|
public Node pop() {
|
||||||
|
Node oldHead;
|
||||||
|
Node newHead;
|
||||||
|
do {
|
||||||
|
oldHead = top.get();
|
||||||
|
if (oldHead == null) {
|
||||||
|
System.out.println(Thread.currentThread().getName() + " 尝试弹出,但栈为空!");
|
||||||
|
return null;
|
||||||
|
}
|
||||||
|
newHead = oldHead.next;
|
||||||
|
System.out.println(Thread.currentThread().getName() + " 尝试弹出 " + oldHead.item +
|
||||||
|
" (期望栈顶: " + oldHead + ", 更新栈顶至: " + newHead + ")");
|
||||||
|
} while (!top.compareAndSet(oldHead, newHead)); // CAS操作:如果当前栈顶仍是oldHead,则更新为newHead
|
||||||
|
System.out.println(Thread.currentThread().getName() + " 成功弹出: " + oldHead.item + " (当前栈顶: " + top.get() + ")");
|
||||||
|
return oldHead;
|
||||||
|
}
|
||||||
|
|
||||||
|
// 打印栈内容
|
||||||
|
public void printStack() {
|
||||||
|
System.out.print("当前栈: ");
|
||||||
|
Node current = top.get();
|
||||||
|
if (current == null) {
|
||||||
|
System.out.println("空");
|
||||||
|
return;
|
||||||
|
}
|
||||||
|
StringBuilder sb = new StringBuilder();
|
||||||
|
while (current != null) {
|
||||||
|
sb.append(current.item).append(" -> ");
|
||||||
|
current = current.next;
|
||||||
|
}
|
||||||
|
sb.setLength(sb.length() - 4); // 移除最后的 " -> "
|
||||||
|
System.out.println(sb.toString());
|
||||||
|
}
|
||||||
|
|
||||||
|
// 获取栈顶节点
|
||||||
|
public Node getTop() {
|
||||||
|
return top.get();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
public class AbaAppear {
|
||||||
|
public static void main(String[] args) throws InterruptedException {
|
||||||
|
LockFreeStackABA stack = new LockFreeStackABA();
|
||||||
|
|
||||||
|
// 1. 初始状态:栈中逐步压入 A、B、C
|
||||||
|
stack.push("C"); // 栈顶:C
|
||||||
|
stack.push("B"); // 栈顶:B → C
|
||||||
|
stack.push("A"); // 栈顶:A → B → C
|
||||||
|
|
||||||
|
Node originalNodeA = stack.getTop(); // 获取当前栈顶的 A 节点引用
|
||||||
|
|
||||||
|
System.out.println("\n--- 初始栈内容 ---");
|
||||||
|
stack.printStack();
|
||||||
|
|
||||||
|
// 2. 线程1 启动,读取栈顶元素后等待
|
||||||
|
Thread thread1 = new Thread(() -> {
|
||||||
|
Node readNode = stack.getTop(); // 线程1在原栈中看到栈顶元素 A
|
||||||
|
System.out.println("\n线程-1 读取到栈顶节点: " + readNode);
|
||||||
|
try {
|
||||||
|
Thread.sleep(200); // 等待线程2的干扰行为发生
|
||||||
|
} catch (InterruptedException e) {
|
||||||
|
e.printStackTrace();
|
||||||
|
}
|
||||||
|
System.out.println("\n线程-1 开始尝试弹出栈顶节点...");
|
||||||
|
Node popNode = stack.pop(); // 线程1尝试弹出栈顶(被线程2修改为新 A)
|
||||||
|
if (readNode == popNode) {
|
||||||
|
System.out.println("同一个节点");
|
||||||
|
}else {
|
||||||
|
System.out.println("不是同一个节点,ABA问题已重现!");
|
||||||
|
}
|
||||||
|
}, "线程-1");
|
||||||
|
|
||||||
|
// 3. 线程2 启动,执行 ABA 序列
|
||||||
|
Thread thread2 = new Thread(() -> {
|
||||||
|
System.out.println("\n--- 线程-2 执行 ABA 序列 ---");
|
||||||
|
stack.pop(); // 弹出 A,栈顶变为 B
|
||||||
|
stack.pop(); // 弹出 B,栈顶变为 C
|
||||||
|
stack.push("X"); // 压入一个新节点 X,栈顶变为 X → C
|
||||||
|
stack.push("A"); // 再压入一个新的 A,栈顶变为 A → X → C
|
||||||
|
System.out.println("--- 线程-2 完成 ABA 序列 ---");
|
||||||
|
stack.printStack();
|
||||||
|
}, "线程-2");
|
||||||
|
|
||||||
|
thread1.start(); // 启动线程1
|
||||||
|
thread2.start(); // 启动线程2
|
||||||
|
|
||||||
|
thread1.join(); // 等待线程1完成
|
||||||
|
thread2.join(); // 等待线程2完成
|
||||||
|
|
||||||
|
System.out.println("\n--- 最终栈内容 ---");
|
||||||
|
stack.printStack();
|
||||||
|
System.out.println("当前栈顶节点: " + stack.getTop());
|
||||||
|
if (stack.getTop() != null) {
|
||||||
|
System.out.println("栈顶节点的 next: " + stack.getTop().next);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
# 如何解决ABA问题
|
||||||
|
|
||||||
|
解决ABA问题的主要方法是引入一个 版本号(或时间戳) 机制。每次修改变量时,不仅修改值,也同时修改版本号。CAS操作时,需要同时比较值和版本号。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
使用AtomicStampedReference解决问题
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.aba;
|
||||||
|
|
||||||
|
import lombok.extern.slf4j.Slf4j;
|
||||||
|
|
||||||
|
import java.util.concurrent.TimeUnit;
|
||||||
|
import java.util.concurrent.atomic.AtomicStampedReference;
|
||||||
|
|
||||||
|
@Slf4j
|
||||||
|
public class AbaSolve {
|
||||||
|
static AtomicStampedReference<String> ref = new AtomicStampedReference<>("A", 0);
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
log.debug("main start ....");
|
||||||
|
String prev = ref.getReference();
|
||||||
|
int stamp = ref.getStamp();
|
||||||
|
log.debug("stamp: {}", stamp);
|
||||||
|
|
||||||
|
other();
|
||||||
|
try {
|
||||||
|
TimeUnit.SECONDS.sleep(1);
|
||||||
|
} catch (InterruptedException e) {
|
||||||
|
throw new RuntimeException(e);
|
||||||
|
}
|
||||||
|
log.debug("change A -> C {} ", ref.compareAndSet(prev, "C", stamp, stamp + 1));
|
||||||
|
}
|
||||||
|
|
||||||
|
private static void other() {
|
||||||
|
new Thread(() -> {
|
||||||
|
int stamp = ref.getStamp();
|
||||||
|
log.debug("{} 's stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||||
|
log.debug("change A-> B {} ", ref.compareAndSet(ref.getReference(), "B", stamp, stamp + 1));
|
||||||
|
stamp = ref.getStamp();
|
||||||
|
log.debug("{} 's changed stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||||
|
}, "t1").start();
|
||||||
|
try {
|
||||||
|
TimeUnit.MILLISECONDS.sleep(500);
|
||||||
|
} catch (InterruptedException e) {
|
||||||
|
throw new RuntimeException(e);
|
||||||
|
}
|
||||||
|
new Thread(()->{
|
||||||
|
int stamp = ref.getStamp();
|
||||||
|
log.debug("{} 's stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||||
|
log.debug("change B->A {}",ref.compareAndSet(ref.getReference(),"A",stamp,stamp + 1));
|
||||||
|
stamp = ref.getStamp();
|
||||||
|
log.debug("{} 's changed stamp is : {}",Thread.currentThread().getName(),stamp);
|
||||||
|
},"t2").start();
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
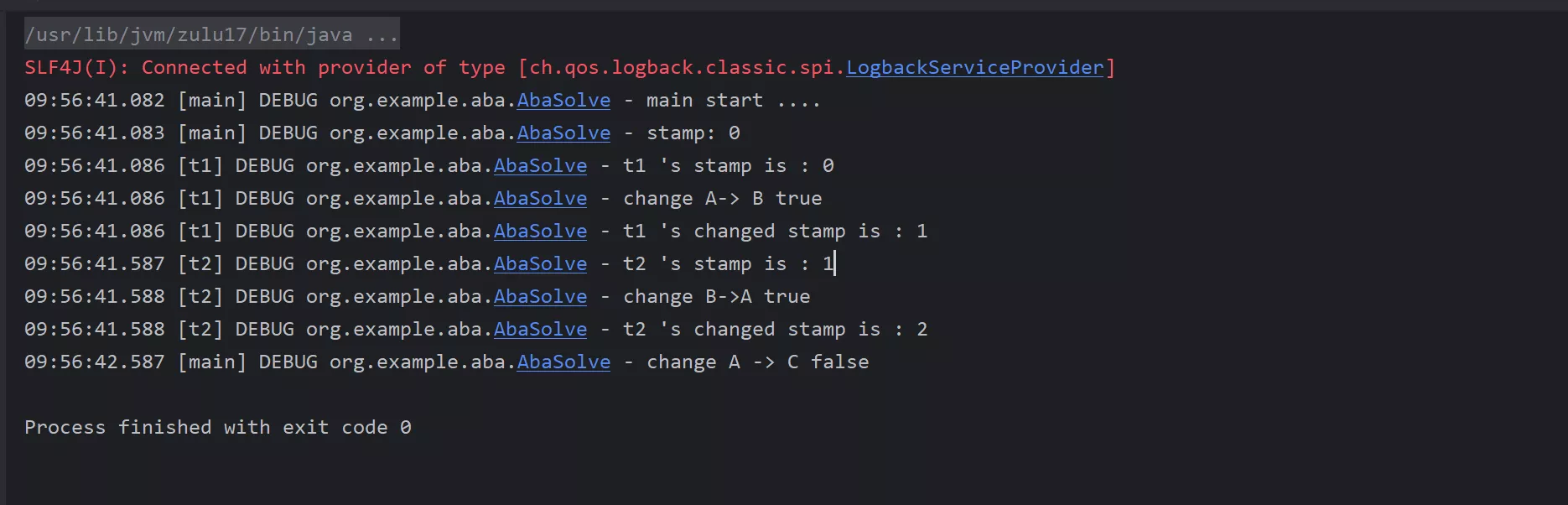
|
||||||
File diff suppressed because it is too large
Load Diff
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [GC,JAVA,JVM]
|
tags: [GC,JAVA,JVM]
|
||||||
category: 'Java'
|
category: 'Java > JVM'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -115,4 +115,3 @@ lang: ''
|
|||||||
- **注意:**
|
- **注意:**
|
||||||
- 此参数在现代的 GC(如 G1)中已不推荐使用或被废弃,因为它们有更智能的回收策略。
|
- 此参数在现代的 GC(如 G1)中已不推荐使用或被废弃,因为它们有更智能的回收策略。
|
||||||
- 在某些情况下,它可能会引入一次额外的、不必要的停顿(Minor GC 的停顿)。因此,除非有明确的测试数据支持,否则一般不建议开启。
|
- 在某些情况下,它可能会引入一次额外的、不必要的停顿(Minor GC 的停顿)。因此,除非有明确的测试数据支持,否则一般不建议开启。
|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [JVM,内存模型]
|
tags: [JVM,内存模型]
|
||||||
category: 'Java'
|
category: 'Java > JVM'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -29,4 +29,3 @@ JVM虚拟机栈:每个线程都有自己独立的Java虚拟机栈,生命周
|
|||||||
本地方法栈: 与Java虚拟机栈差不读多,执行本地方法,其中堆和方法区是线程共有的。
|
本地方法栈: 与Java虚拟机栈差不读多,执行本地方法,其中堆和方法区是线程共有的。
|
||||||
|
|
||||||
Java堆: 存放和管理对象实例,被所有线程共享。
|
Java堆: 存放和管理对象实例,被所有线程共享。
|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [JVM,垃圾回收,分代回收]
|
tags: [JVM,垃圾回收,分代回收]
|
||||||
category: 'Java'
|
category: 'Java > JVM'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -100,6 +100,7 @@ lang: ''
|
|||||||
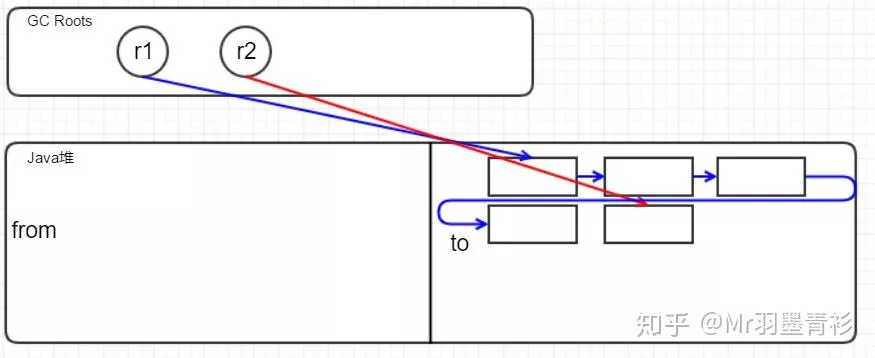
|

|
||||||
|
|
||||||
## **垃圾回收算法之标记-整理算法**
|
## **垃圾回收算法之标记-整理算法**
|
||||||
|
|
||||||
标记-整理算法(Mark-Compact Algorithm) 是一种常见的垃圾回收(GC)算法,主要用于解决 标记-清除算法(Mark-Sweep) 产生的内存碎片问题。它通常被用于 Java 的老年代(Old Generation)垃圾回收中。
|
标记-整理算法(Mark-Compact Algorithm) 是一种常见的垃圾回收(GC)算法,主要用于解决 标记-清除算法(Mark-Sweep) 产生的内存碎片问题。它通常被用于 Java 的老年代(Old Generation)垃圾回收中。
|
||||||
|
|
||||||
标记-整理算法主要分为两大阶段:
|
标记-整理算法主要分为两大阶段:
|
||||||
@@ -145,4 +146,3 @@ lang: ''
|
|||||||
### 分代算法执行过程
|
### 分代算法执行过程
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [Java,类加载器,ClassLoader,双亲委派机制]
|
tags: [Java,类加载器,ClassLoader,双亲委派机制]
|
||||||
category: 'Java'
|
category: 'Java > JVM'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -38,4 +38,3 @@ Java类加载器从高到低分为以下层级(以JDK 8为例):
|
|||||||
1. **保障核心类库的安全**防止用户自定义的类(如`java.lang.Object`)覆盖JVM核心类。例如,如果用户编写了一个恶意`String`类,双亲委派机制会优先加载核心库中的`String`,从而避免安全隐患。
|
1. **保障核心类库的安全**防止用户自定义的类(如`java.lang.Object`)覆盖JVM核心类。例如,如果用户编写了一个恶意`String`类,双亲委派机制会优先加载核心库中的`String`,从而避免安全隐患。
|
||||||
2. **避免重复加载**同一个类只会被一个类加载器加载一次,防止内存中出现多个相同类的副本,确保类的唯一性。
|
2. **避免重复加载**同一个类只会被一个类加载器加载一次,防止内存中出现多个相同类的副本,确保类的唯一性。
|
||||||
3. **实现代码隔离**不同类加载器加载的类属于不同的命名空间,天然支持模块化(如Tomcat为每个Web应用分配独立的类加载器)。
|
3. **实现代码隔离**不同类加载器加载的类属于不同的命名空间,天然支持模块化(如Tomcat为每个Web应用分配独立的类加载器)。
|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [分代回收,JVM]
|
tags: [分代回收,JVM]
|
||||||
category: 'Java'
|
category: 'Java > JVM'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -56,7 +56,7 @@ JVM 内置的通用垃圾回收原则。堆内存划分为 Eden、Survivor(年
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
核心规则:
|
核心规则:
|
||||||
|
|
||||||
1. 对象优先在Eden区分配
|
1. 对象优先在Eden区分配
|
||||||
2. 大对象直接进入老年代
|
2. 大对象直接进入老年代
|
||||||
@@ -66,7 +66,7 @@ JVM 内置的通用垃圾回收原则。堆内存划分为 Eden、Survivor(年
|
|||||||
在 JVM 中,**年龄阈值(Tenuring Threshold)** 是一个关键的参数,它决定了新生代(Young Generation)中的对象需要经历多少次垃圾回收(Minor GC)仍然存活,才会被晋升(Promotion)到老年代(Old Generation)。
|
在 JVM 中,**年龄阈值(Tenuring Threshold)** 是一个关键的参数,它决定了新生代(Young Generation)中的对象需要经历多少次垃圾回收(Minor GC)仍然存活,才会被晋升(Promotion)到老年代(Old Generation)。
|
||||||
|
|
||||||
年轻代分为Eden区和Survivor区,Survivor区又分为S0,S1,S0,S1其中一个作为使用区(from),一个作为空闲区(to)(不固定,可能S0是空闲区,也可能是使用区)
|
年轻代分为Eden区和Survivor区,Survivor区又分为S0,S1,S0,S1其中一个作为使用区(from),一个作为空闲区(to)(不固定,可能S0是空闲区,也可能是使用区)
|
||||||
在Minor GC开始以后(会回收Eden区和使用区中的对象),逃过第一轮GC的,在Eden区和使用区中的对象,会被丢在空闲区,接下来将使用区和空闲区互换(空闲区变使用区,使用区变空闲区),等待下一次Eden区满进行Minor GC,以此不断循环(每复制一次,年龄就会 + 1)
|
在Minor GC开始以后(会回收Eden区和使用区中的对象),逃过第一轮GC的,在Eden区和使用区中的对象,会被丢在空闲区,接下来将使用区和空闲区互换(空闲区变使用区,使用区变空闲区),等待下一次Eden区满进行Minor GC,以此不断循环(每复制一次,年龄就会 + 1)
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@@ -77,4 +77,3 @@ JVM 内置的通用垃圾回收原则。堆内存划分为 Eden、Survivor(年
|
|||||||
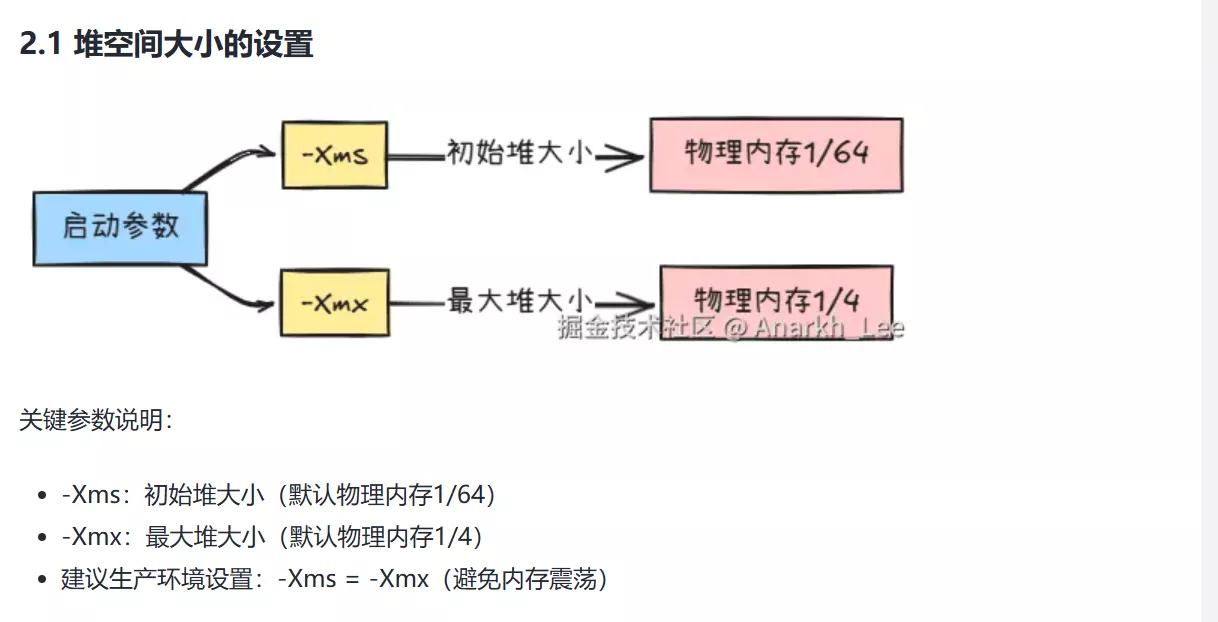
|

|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [Java,JVM,垃圾收集器]
|
tags: [Java,JVM,垃圾收集器]
|
||||||
category: 'Java'
|
category: 'Java > JVM'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -41,4 +41,4 @@ serial的老年代版本,使用整理算法。
|
|||||||
|
|
||||||
# G1垃圾回收器
|
# G1垃圾回收器
|
||||||
|
|
||||||
[G1垃圾回收](Java%E4%B8%AD%E5%B8%B8%E8%A7%81%E7%9A%84%E5%9E%83%E5%9C%BE%E6%94%B6%E9%9B%86%E5%99%A8%2022a49a1194e98020a75ced52b5d871d7/G1%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%2022a49a1194e980e9bbf7e2a6c0f3e4c6.md)
|
[G1垃圾回收](Java%E4%B8%AD%E5%B8%B8%E8%A7%81%E7%9A%84%E5%9E%83%E5%9C%BE%E6%94%B6%E9%9B%86%E5%99%A8%2022a49a1194e98020a75ced52b5d871d7/G1%E5%9E%83%E5%9C%BE%E5%9B%9E%E6%94%B6%2022a49a1194e980e9bbf7e2a6c0f3e4c6.md)
|
||||||
372
src/content/posts/Java/Java函数式接口.md
Normal file
372
src/content/posts/Java/Java函数式接口.md
Normal file
@@ -0,0 +1,372 @@
|
|||||||
|
---
|
||||||
|
title: Java函数式接口
|
||||||
|
published: 2025-07-19
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [函数式接口, Java, 编程]
|
||||||
|
category: 'Java'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
|
||||||
|
<https://www.cnblogs.com/dgwblog/p/11739500.html>
|
||||||
|
|
||||||
|
<https://juejin.cn/post/6844903892166148110>
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 1. `Supplier<T>` - 数据的供给者 🎁
|
||||||
|
|
||||||
|
**接口定义**:`@FunctionalInterface public interface Supplier<T> { T get(); }`
|
||||||
|
|
||||||
|
**核心作用**:
|
||||||
|
`Supplier` 接口的核心职责是**生产或提供数据**,它不接受任何参数,但会返回一个 `T` 类型的结果。你可以把它想象成一个“工厂”或者“源头”,当你需要一个特定类型的对象时,就调用它的 `get()` 方法。
|
||||||
|
|
||||||
|
**方法详解**:
|
||||||
|
|
||||||
|
* `T get()`: 这是 `Supplier` 接口中唯一的抽象方法。调用它时,会执行你提供的 Lambda 表达式或方法引用所定义的逻辑,并返回一个结果。
|
||||||
|
|
||||||
|
**常见应用场景**:
|
||||||
|
|
||||||
|
* **延迟加载/创建对象**:当某个对象的创建成本较高,或者并非立即需要时,可以使用 `Supplier` 来推迟其创建,直到真正使用时才调用 `get()`。
|
||||||
|
* **生成默认值或配置信息**:提供一个默认对象或从某个源(如配置文件、数据库)获取配置。
|
||||||
|
* **生成随机数据**:如示例中的随机数生成器。
|
||||||
|
* **作为工厂方法**:在更复杂的场景中,`Supplier` 可以作为创建对象的简单工厂。
|
||||||
|
|
||||||
|
**您的示例代码分析** (`SupplierExample.java`):
|
||||||
|
|
||||||
|
```java
|
||||||
|
import java.util.Random;
|
||||||
|
import java.util.function.Supplier;
|
||||||
|
|
||||||
|
public class SupplierExample {
|
||||||
|
|
||||||
|
// 示例方法1: 接收一个 Supplier 来获取随机整数
|
||||||
|
public static Integer getRandomNumber(Supplier<Integer> randomNumberSupplier) {
|
||||||
|
// 调用 randomNumberSupplier 的 get 方法来执行其提供的逻辑
|
||||||
|
return randomNumberSupplier.get();
|
||||||
|
}
|
||||||
|
|
||||||
|
// 示例方法2: 接收一个 Supplier 来创建问候语字符串
|
||||||
|
public static String createGreetingMessage(Supplier<String> greetingSupplier) {
|
||||||
|
return greetingSupplier.get();
|
||||||
|
}
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
// 场景1: 获取随机数
|
||||||
|
// Lambda 表达式实现 Supplier: () -> new Random().nextInt(100)
|
||||||
|
// 这个 Lambda 不接受参数,返回一个 0-99 的随机整数
|
||||||
|
Supplier<Integer> randomIntSupplier = () -> new Random().nextInt(100);
|
||||||
|
Integer num = getRandomNumber(randomIntSupplier); // 传递行为
|
||||||
|
System.out.println("随机数: " + num);
|
||||||
|
|
||||||
|
// 场景2: 获取固定数字
|
||||||
|
// Lambda 表达式实现 Supplier: () -> 42
|
||||||
|
// 这个 Lambda 总是返回固定的数字 42
|
||||||
|
Supplier<Integer> fixedIntSupplier = () -> 42;
|
||||||
|
Integer fixedNum = getRandomNumber(fixedIntSupplier);
|
||||||
|
System.out.println("固定数字: " + fixedNum);
|
||||||
|
|
||||||
|
// 场景3: 创建不同的问候语
|
||||||
|
Supplier<String> englishGreeting = () -> "Hello, World!";
|
||||||
|
System.out.println(createGreetingMessage(englishGreeting)); // 输出: Hello, World!
|
||||||
|
|
||||||
|
Supplier<String> spanishGreeting = () -> "¡Hola, Mundo!";
|
||||||
|
System.out.println(createGreetingMessage(spanishGreeting)); // 输出: ¡Hola, Mundo!
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**代码解读**:
|
||||||
|
|
||||||
|
* `getRandomNumber` 和 `createGreetingMessage` 方法本身并不关心数字或字符串是如何产生的,它们只依赖传入的 `Supplier` 来提供结果。这体现了**行为参数化**——方法接受行为(通过函数式接口)作为参数。
|
||||||
|
* 在 `main` 方法中:
|
||||||
|
* `randomIntSupplier`: 定义了一个行为——“生成一个0到99的随机整数”。
|
||||||
|
* `fixedIntSupplier`: 定义了另一个行为——“总是提供数字42”。
|
||||||
|
* `englishGreeting` 和 `spanishGreeting`: 定义了不同的行为来提供特定的字符串。
|
||||||
|
* 通过将不同的 `Supplier` 实现传递给同一个方法 (`getRandomNumber` 或 `createGreetingMessage`),我们可以获得不同的结果,而无需修改方法本身。
|
||||||
|
|
||||||
|
**关键益处**:
|
||||||
|
|
||||||
|
* **灵活性**:可以轻松替换不同的供给逻辑。
|
||||||
|
* **解耦**:数据的使用者和数据的生产者解耦。
|
||||||
|
* **可测试性**:可以方便地传入 mock 的 `Supplier` 进行单元测试。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 2. `Function<T, R>` - 数据的转换器/映射器 🔄
|
||||||
|
|
||||||
|
**接口定义**:`@FunctionalInterface public interface Function<T, R> { R apply(T t); }`
|
||||||
|
|
||||||
|
**核心作用**:
|
||||||
|
`Function` 接口的核心职责是**将一个类型 `T` 的输入参数转换或映射成另一个类型 `R` 的输出结果**。它就像一个数据处理管道中的一个环节,接收数据,进行处理,然后传递给下一个环节。
|
||||||
|
|
||||||
|
**方法详解**:
|
||||||
|
|
||||||
|
* `R apply(T t)`: 这是 `Function` 的核心方法。它接受一个 `T` 类型的参数 `t`,对其执行Lambda表达式或方法引用中定义的转换逻辑,并返回一个 `R` 类型的结果。
|
||||||
|
|
||||||
|
**常见应用场景**:
|
||||||
|
|
||||||
|
* **数据转换**:例如,将字符串转换为整数,将日期对象格式化为字符串,或者如示例中计算字符串长度、数字平方。
|
||||||
|
* **对象属性提取**:从一个复杂对象中提取某个特定属性的值。例如,`Person -> String (person.getName())`。
|
||||||
|
* **链式操作**:`Function` 接口提供了 `andThen()` 和 `compose()` 默认方法,可以方便地将多个 `Function` 串联起来形成一个处理流水线。
|
||||||
|
|
||||||
|
**您的示例代码分析** (`FunctionExample.java`):
|
||||||
|
|
||||||
|
```java
|
||||||
|
import java.util.function.Function;
|
||||||
|
|
||||||
|
public class FunctionExample {
|
||||||
|
|
||||||
|
// 示例方法1: 接收一个 Function 来计算字符串长度
|
||||||
|
public static Integer getStringLength(String text, Function<String, Integer> lengthCalculator) {
|
||||||
|
// 调用 lengthCalculator 的 apply 方法,传入 text,执行其转换逻辑
|
||||||
|
return lengthCalculator.apply(text);
|
||||||
|
}
|
||||||
|
|
||||||
|
// 示例方法2: 接收一个 Function 来计算数字的平方
|
||||||
|
public static Integer squareNumber(Integer number, Function<Integer, Integer> squareFunction) {
|
||||||
|
return squareFunction.apply(number);
|
||||||
|
}
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
// 场景1: 计算字符串长度
|
||||||
|
String myString = "Java Functional";
|
||||||
|
// Lambda 表达式实现 Function: s -> s.length()
|
||||||
|
// 这个 Lambda 接受一个 String s,返回其长度 (Integer)
|
||||||
|
Function<String, Integer> lengthLambda = s -> s.length();
|
||||||
|
Integer length = getStringLength(myString, lengthLambda);
|
||||||
|
System.out.println("字符串 '" + myString + "' 的长度是: " + length);
|
||||||
|
|
||||||
|
// 使用方法引用 (Method Reference) 实现 Function: String::length
|
||||||
|
// String::length 等价于 s -> s.length(),更为简洁
|
||||||
|
Integer lengthUsingMethodRef = getStringLength("Test", String::length);
|
||||||
|
System.out.println("字符串 'Test' 的长度是: " + lengthUsingMethodRef);
|
||||||
|
|
||||||
|
// 场景2: 计算数字平方
|
||||||
|
Integer num = 5;
|
||||||
|
// Lambda 表达式实现 Function: n -> n * n
|
||||||
|
// 接受一个 Integer n,返回 n 的平方 (Integer)
|
||||||
|
Function<Integer, Integer> squareLambda = n -> n * n;
|
||||||
|
Integer squared = squareNumber(num, squareLambda);
|
||||||
|
System.out.println(num + " 的平方是: " + squared);
|
||||||
|
|
||||||
|
Integer anotherNum = 10;
|
||||||
|
// 多行 Lambda 表达式
|
||||||
|
Function<Integer, Integer> verboseSquareLambda = x -> {
|
||||||
|
System.out.println("正在计算 " + x + " 的平方..."); // Lambda 可以包含多条语句
|
||||||
|
return x * x;
|
||||||
|
};
|
||||||
|
Integer squaredAgain = squareNumber(anotherNum, verboseSquareLambda);
|
||||||
|
System.out.println(anotherNum + " 的平方是: " + squaredAgain);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**代码解读**:
|
||||||
|
|
||||||
|
* `getStringLength` 和 `squareNumber` 方法定义了操作的框架,但具体的转换逻辑由传入的 `Function` 对象决定。
|
||||||
|
* 在 `main` 方法中:
|
||||||
|
* `s -> s.length()` 和 `String::length` 都是 `Function<String, Integer>` 的实例,它们定义了“从字符串到其长度整数”的转换。
|
||||||
|
* `n -> n * n` 是 `Function<Integer, Integer>` 的实例,定义了“从整数到其平方整数”的转换。
|
||||||
|
* 多行 Lambda `verboseSquareLambda` 展示了更复杂的转换逻辑可以被封装。
|
||||||
|
* 这种方式使得我们可以为同一个通用方法(如 `getStringLength`)提供不同的转换策略。
|
||||||
|
|
||||||
|
**关键益处**:
|
||||||
|
|
||||||
|
* **代码复用**:通用的转换逻辑可以被封装成 `Function` 并在多处使用。
|
||||||
|
* **可组合性**:通过 `andThen` 和 `compose` 可以构建复杂的转换流。
|
||||||
|
* **清晰性**:将数据转换的意图明确表达出来。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 3. `BiConsumer<T, U>` - 双参数的消费者/执行者 🤝
|
||||||
|
|
||||||
|
**接口定义**:`@FunctionalInterface public interface BiConsumer<T, U> { void accept(T t, U u); }`
|
||||||
|
|
||||||
|
**核心作用**:
|
||||||
|
`BiConsumer` 接口的核心职责是**对两个不同类型(或相同类型)的输入参数 `T` 和 `U` 执行某个操作或产生某种副作用,但它不返回任何结果 (void)**。你可以把它看作是需要两个输入才能完成其工作的“执行者”。
|
||||||
|
|
||||||
|
**方法详解**:
|
||||||
|
|
||||||
|
* `void accept(T t, U u)`: 这是 `BiConsumer` 的核心方法。它接受两个参数 `t` 和 `u`,并对它们执行 Lambda 表达式或方法引用中定义的操作。由于返回类型是 `void`,它通常用于执行有副作用的操作,如打印、修改集合、更新数据库等。
|
||||||
|
|
||||||
|
**常见应用场景**:
|
||||||
|
|
||||||
|
* **处理键值对**:非常适合用于迭代 `Map` 的条目,如 `Map.forEach()` 方法就接受一个 `BiConsumer<K, V>`。
|
||||||
|
* **同时操作两个相关对象**:当一个操作需要两个输入,并且不产生新的独立结果时。例如,将一个对象的属性设置到另一个对象上。
|
||||||
|
* **配置或初始化**:使用两个参数来配置某个组件。
|
||||||
|
|
||||||
|
**您的示例代码分析** (`BiConsumerExample.java`):
|
||||||
|
|
||||||
|
```java
|
||||||
|
import java.util.HashMap;
|
||||||
|
import java.util.Map;
|
||||||
|
import java.util.function.BiConsumer;
|
||||||
|
|
||||||
|
public class BiConsumerExample {
|
||||||
|
|
||||||
|
// 示例方法1: 接收 BiConsumer 来打印键和值
|
||||||
|
public static <K, V> void printMapEntry(K key, V value, BiConsumer<K, V> entryPrinter) {
|
||||||
|
// 调用 entryPrinter 的 accept 方法,传入 key 和 value
|
||||||
|
entryPrinter.accept(key, value);
|
||||||
|
}
|
||||||
|
|
||||||
|
// 示例2 在 main 中直接演示了更常见的 Map 操作方式
|
||||||
|
|
||||||
|
// 辅助内部类,如果 BiConsumer 需要一次性接收多个信息 (在此示例中未直接用于核心 BiConsumer 演示)
|
||||||
|
// static class Pair<F, S> {
|
||||||
|
// F first; S second;
|
||||||
|
// Pair(F f, S s) { this.first = f; this.second = s; }
|
||||||
|
// }
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
// 场景1: 使用 printMapEntry 打印键值
|
||||||
|
// Lambda 表达式实现 BiConsumer: (k, v) -> System.out.println("键: " + k + ", 值: " + v)
|
||||||
|
// 接受一个 String k 和一个 Integer v,然后打印它们
|
||||||
|
BiConsumer<String, Integer> simplePrinter = (k, v) -> System.out.println("键: " + k + ", 值: " + v);
|
||||||
|
printMapEntry("年龄", 30, simplePrinter);
|
||||||
|
printMapEntry("数量", 100, simplePrinter);
|
||||||
|
|
||||||
|
// 场景2: 使用 BiConsumer 来填充 Map
|
||||||
|
Map<String, String> config = new HashMap<>();
|
||||||
|
// Lambda 表达式实现 BiConsumer: (key, value) -> config.put(key, value)
|
||||||
|
// 这个 Lambda 捕获了外部的 'config' Map 对象。
|
||||||
|
// 它接受 String key 和 String value,并将它们放入 config Map 中。
|
||||||
|
BiConsumer<String, String> mapPutter = (key, value) -> config.put(key, value);
|
||||||
|
|
||||||
|
mapPutter.accept("user.name", "Alice"); // 执行操作:config.put("user.name", "Alice")
|
||||||
|
mapPutter.accept("user.role", "Admin"); // 执行操作:config.put("user.role", "Admin")
|
||||||
|
System.out.println("配置Map: " + config);
|
||||||
|
|
||||||
|
// 场景3: Map.forEach() 的典型用法
|
||||||
|
// Map 的 forEach 方法直接接受一个 BiConsumer<K, V>
|
||||||
|
System.out.println("遍历Map:");
|
||||||
|
config.forEach((key, value) -> { // 这里的 (key, value) -> {...} 就是一个 BiConsumer
|
||||||
|
System.out.println("配置项 - " + key + ": " + value);
|
||||||
|
});
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**代码解读**:
|
||||||
|
|
||||||
|
* `printMapEntry` 方法接受一个键、一个值和一个 `BiConsumer`,该 `BiConsumer` 定义了如何处理这对键值。
|
||||||
|
* 在 `main` 方法中:
|
||||||
|
* `simplePrinter`: 定义了一个行为——“接收一个键和一个值,并将它们打印到控制台”。
|
||||||
|
* `mapPutter`: 定义了一个行为——“接收一个键和一个字符串值,并将它们存入外部的 `config` Map”。这里 Lambda 表达式捕获了外部变量 `config`,这是一种常见的用法。
|
||||||
|
* `config.forEach(...)`: 这是 `BiConsumer` 最经典的用例之一。`forEach` 方法遍历 `Map` 中的每个条目,并对每个键值对执行提供的 `BiConsumer` 逻辑。
|
||||||
|
|
||||||
|
**关键益处**:
|
||||||
|
|
||||||
|
* **处理成对数据**:专门设计用于需要两个输入的场景。
|
||||||
|
* **与集合(尤其是Map)的良好集成**:`Map.forEach` 是一个很好的例子。
|
||||||
|
* **封装副作用操作**:可以将对两个参数的副作用操作(如修改、打印)封装起来。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
## 4. `Consumer<T>` - 数据的消费者/执行者 🍽️
|
||||||
|
|
||||||
|
**接口定义**:`@FunctionalInterface public interface Consumer<T> { void accept(T t); }`
|
||||||
|
|
||||||
|
**核心作用**:
|
||||||
|
`Consumer` 接口的核心职责是**对单个输入参数 `T` 执行某个操作或产生某种副作用,它不返回任何结果 (void)**。你可以把它看作是数据的“终点”或某个动作的执行者,它“消费”数据但不产生新的输出数据。
|
||||||
|
|
||||||
|
**方法详解**:
|
||||||
|
|
||||||
|
* `void accept(T t)`: 这是 `Consumer` 的核心方法。它接受一个 `T` 类型的参数 `t`,并对其执行 Lambda 表达式或方法引用中定义的操作。因为返回 `void`,它主要用于执行那些为了副作用而进行的操作(如打印、修改对象状态、写入文件等)。
|
||||||
|
|
||||||
|
**常见应用场景**:
|
||||||
|
|
||||||
|
* **迭代集合并处理元素**:`List.forEach()` 方法接受一个 `Consumer<T>`,对列表中的每个元素执行指定操作。
|
||||||
|
* **打印/日志记录**:将信息输出到控制台、文件或其他日志系统。
|
||||||
|
* **更新对象状态**:修改传入对象的属性。
|
||||||
|
* **回调**:在某个异步操作完成后执行一个 `Consumer` 定义的动作。
|
||||||
|
|
||||||
|
**您的示例代码分析** (`ConsumerExample.java`):
|
||||||
|
|
||||||
|
```java
|
||||||
|
import java.util.Arrays;
|
||||||
|
import java.util.List;
|
||||||
|
import java.util.function.Consumer;
|
||||||
|
|
||||||
|
public class ConsumerExample {
|
||||||
|
|
||||||
|
// 示例方法1: 接收 Consumer 来展示单个项目
|
||||||
|
public static <T> void displayItem(T item, Consumer<T> itemDisplayer) {
|
||||||
|
// 调用 itemDisplayer 的 accept 方法,传入 item,执行其消费逻辑
|
||||||
|
itemDisplayer.accept(item);
|
||||||
|
}
|
||||||
|
|
||||||
|
// 示例方法2: 接收 Consumer 来处理列表中的每个项目
|
||||||
|
public static <T> void processListItems(List<T> list, Consumer<T> itemProcessor) {
|
||||||
|
for (T item : list) {
|
||||||
|
itemProcessor.accept(item); // 对列表中的每个 item 执行 itemProcessor 的逻辑
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
public static void main(String[] args) {
|
||||||
|
// 场景1: 使用 displayItem 打印信息
|
||||||
|
// Lambda 表达式实现 Consumer: message -> System.out.println("消息: " + message)
|
||||||
|
// 接受一个 String message,然后打印它
|
||||||
|
Consumer<String> consolePrinter = message -> System.out.println("消息: " + message);
|
||||||
|
displayItem("你好,函数式接口!", consolePrinter);
|
||||||
|
|
||||||
|
// 多行 Lambda 实现 Consumer,进行更复杂的打印
|
||||||
|
Consumer<Integer> detailedPrinter = number -> {
|
||||||
|
System.out.println("--- 数字详情 ---");
|
||||||
|
System.out.println("值: " + number);
|
||||||
|
System.out.println("是否偶数: " + (number % 2 == 0));
|
||||||
|
System.out.println("----------------");
|
||||||
|
};
|
||||||
|
displayItem(10, detailedPrinter);
|
||||||
|
displayItem(7, System.out::println); // 方法引用: System.out::println 等价于 x -> System.out.println(x)
|
||||||
|
|
||||||
|
// 场景2: 使用 processListItems 处理列表
|
||||||
|
List<String> names = Arrays.asList("爱丽丝", "鲍勃", "查理");
|
||||||
|
|
||||||
|
System.out.println("\n打印名字:");
|
||||||
|
// Lambda: name -> System.out.println("你好, " + name + "!")
|
||||||
|
// 对列表中的每个名字,执行打印问候语的操作
|
||||||
|
processListItems(names, name -> System.out.println("你好, " + name + "!"));
|
||||||
|
|
||||||
|
System.out.println("\n将名字转换为大写并打印 (仅打印,不修改原列表):");
|
||||||
|
// Lambda: name -> System.out.println(name.toUpperCase())
|
||||||
|
// 对列表中的每个名字,先转大写,然后打印
|
||||||
|
processListItems(names, name -> System.out.println(name.toUpperCase()));
|
||||||
|
|
||||||
|
// Consumer 也可以有副作用,比如修改外部状态 (通常需谨慎使用以避免复杂性)
|
||||||
|
StringBuilder allNames = new StringBuilder();
|
||||||
|
// Lambda: name -> allNames.append(name).append(" ")
|
||||||
|
// 这个 Consumer 修改了外部的 allNames 对象
|
||||||
|
processListItems(names, name -> allNames.append(name).append(" "));
|
||||||
|
System.out.println("\n拼接所有名字: " + allNames.toString().trim());
|
||||||
|
|
||||||
|
// List.forEach 的典型用法
|
||||||
|
System.out.println("\n使用 List.forEach 打印名字(大写):");
|
||||||
|
names.forEach(name -> System.out.println(name.toUpperCase())); // name -> System.out.println(...) 是一个Consumer
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
**代码解读**:
|
||||||
|
|
||||||
|
* `displayItem` 方法接受一个项目和一个 `Consumer`,该 `Consumer` 定义了如何“消费”或处理这个项目。
|
||||||
|
* `processListItems` 方法遍历列表,并对每个元素应用传入的 `Consumer` 逻辑。这与 `List.forEach()` 的行为非常相似。
|
||||||
|
* 在 `main` 方法中:
|
||||||
|
* `consolePrinter` 和 `detailedPrinter` 定义了不同的打印行为。`System.out::println` 是一个简洁的方法引用,用于直接打印。
|
||||||
|
* 在处理 `names` 列表时,通过传递不同的 `Consumer` 给 `processListItems`,实现了不同的处理逻辑(简单问候、转换为大写打印、追加到 `StringBuilder`)。
|
||||||
|
* `allNames.append(...)` 的例子展示了 `Consumer` 如何产生副作用(修改外部对象的状态)。虽然强大,但在复杂系统中应谨慎使用副作用,以保持代码的可预测性。
|
||||||
|
* `names.forEach(...)` 直接使用了 `List` 接口内置的 `forEach` 方法,该方法就接受一个 `Consumer`。
|
||||||
|
|
||||||
|
**关键益处**:
|
||||||
|
|
||||||
|
* **执行动作**:非常适合表示对数据执行的无返回值的操作。
|
||||||
|
* **迭代与处理**:与集合框架(如 `List.forEach`)完美配合,简化迭代代码。
|
||||||
|
* **封装副作用**:将有副作用的操作(如I/O、UI更新)封装到 `Consumer` 中,使得代码意图更清晰。
|
||||||
|
|
||||||
|
---
|
||||||
74
src/content/posts/Java/深入理解Java反射与泛型_类型擦除与强制类型转换.md
Normal file
74
src/content/posts/Java/深入理解Java反射与泛型_类型擦除与强制类型转换.md
Normal file
@@ -0,0 +1,74 @@
|
|||||||
|
---
|
||||||
|
title: 深入理解Java反射与泛型_类型擦除与强制类型转换
|
||||||
|
published: 2025-07-19
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [反射, 泛型, 类型擦除, 强制类型转换]
|
||||||
|
category: 'Java'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
|
||||||
|
|
||||||
|
# 深入理解Java反射与泛型:类型擦除与强制类型转换
|
||||||
|
|
||||||
|
在 Java 编程中,反射(Reflection)和泛型(Generics)是两个强大且常用的特性。反射允许我们在运行时检查和操作类、方法、字段等,而泛型则允许我们编写更加通用和类型安全的代码。然而,Java 的泛型机制与类型擦除(Type Erasure)密切相关,这使得泛型在反射中的应用变得复杂。本文将深入探讨 Java 反射与泛型的结合使用,特别是类型擦除的影响以及如何通过强制类型转换来解决这些问题。
|
||||||
|
|
||||||
|
## 1. 泛型简介
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
## 类型擦除
|
||||||
|
|
||||||
|
### 1. 什么是类型擦除?
|
||||||
|
|
||||||
|
类型擦除(Type Erasure)是 Java 泛型的核心机制。它指的是**在编译阶段,Java 会移除所有泛型类型信息**,即只在源代码层面检查泛型参数的类型,到了运行时,相关类型信息就被“擦除”掉了。
|
||||||
|
|
||||||
|
### 2. 为什么会有类型擦除?
|
||||||
|
|
||||||
|
Java 为了兼容早期版本(Java 5 之前没有泛型),采用了类型擦除的方式实现泛型,这样泛型代码能够和老代码共存而不冲突。
|
||||||
|
|
||||||
|
### 3. 类型擦除具体表现
|
||||||
|
|
||||||
|
- **编译后不保留泛型类型参数信息。**
|
||||||
|
示例:
|
||||||
|
|
||||||
|
```java
|
||||||
|
List<String> stringList = new ArrayList<>();
|
||||||
|
List<Integer> integerList = new ArrayList<>();
|
||||||
|
System.out.println(stringList.getClass() == integerList.getClass()); // true
|
||||||
|
```
|
||||||
|
|
||||||
|
运行时 `stringList` 和 `integerList` 其实都是 `ArrayList` 类型,不区分里面装的东西。
|
||||||
|
|
||||||
|
- **泛型类的字节码文件和“裸类型”一致。**
|
||||||
|
例如 `List<String>`、`List<Integer>`、`List<Double>` 会被编译成一样的 `List` 类。
|
||||||
|
|
||||||
|
- **方法中的类型参数会被替换成它的限定类型(如果有),否则直接替换为 Object。**
|
||||||
|
|
||||||
|
```java
|
||||||
|
class Box<T> {
|
||||||
|
T value;
|
||||||
|
}
|
||||||
|
// 编译后其实相当于
|
||||||
|
class Box {
|
||||||
|
Object value;
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
### 4. 类型擦除带来的影响
|
||||||
|
|
||||||
|
- **运行时无法通过反射获得泛型参数的具体类型。** 除非通过继承和明确指定泛型参数,否则无法在运行时获得泛型具体类型。
|
||||||
|
- **不能直接创建泛型数组。**
|
||||||
|
- **某些类型强制转换失去编译器检查。**
|
||||||
|
|
||||||
|
### 5. 可以通过什么方式间接获取泛型类型?
|
||||||
|
|
||||||
|
- 通过创建“带泛型参数的子类”并用反射获取 `getGenericSuperclass()`,有时可以拿到实际类型参数。
|
||||||
|
- 可以通过一些第三方库(如 Gson、Jackson)的特殊用法间接保存类型信息,但这些都是通过 hack 或特殊设计实现的。
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
### 总结一句话
|
||||||
|
|
||||||
|
Java 泛型只在编译阶段保证类型安全,运行阶段所有泛型信息都会被类型擦除,代码在运行时只知道原始类型,不再区分泛型参数。
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [HashMap,Java]
|
tags: [HashMap,Java]
|
||||||
category: 'Java'
|
category: 'Java > 集合框架'
|
||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
@@ -60,17 +60,21 @@ HashMap的默认初始容量为16,负载因子为0.75,也就是说,当存
|
|||||||
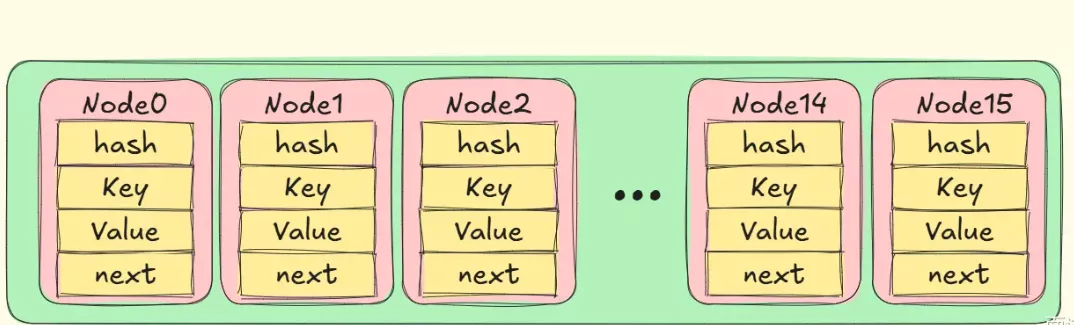
|

|
||||||
|
|
||||||
### 为什么采用数组?
|
### 为什么采用数组?
|
||||||
|
|
||||||
因为数组的随机访问速度非常快,HashMap通过哈希函数将键映射到数组索引位置,从而实现快速查找。
|
因为数组的随机访问速度非常快,HashMap通过哈希函数将键映射到数组索引位置,从而实现快速查找。
|
||||||
|
|
||||||
数组的每一个元素称为一个桶(bucket),对于一个给定的键值对key,value,HashMap会计算出一个哈希值(计算的是key的hash),然后通过`(n-1) & hash`来确定该键值对在数组中的位置。
|
数组的每一个元素称为一个桶(bucket),对于一个给定的键值对key,value,HashMap会计算出一个哈希值(计算的是key的hash),然后通过`(n-1) & hash`来确定该键值对在数组中的位置。
|
||||||
|
|
||||||
### 如何定位key value该存储在桶数组的哪个位置上?(获取index)
|
### 如何定位key value该存储在桶数组的哪个位置上?(获取index)
|
||||||
|
|
||||||
HashMap通过`(n - 1) & hash`来计算索引位置,其中n是数组的长度,hash是键的哈希值。
|
HashMap通过`(n - 1) & hash`来计算索引位置,其中n是数组的长度,hash是键的哈希值。
|
||||||
|
|
||||||
### 如何计算hash值?
|
### 如何计算hash值?
|
||||||
|
|
||||||
HashMap使用键的`hashCode()`方法计算哈希值,然后对哈希值进行扰动处理,最后通过`(n-1) & hash`来确定元素在数组中的存储位置。
|
HashMap使用键的`hashCode()`方法计算哈希值,然后对哈希值进行扰动处理,最后通过`(n-1) & hash`来确定元素在数组中的存储位置。
|
||||||
|
|
||||||
### 为什么要扰动处理?
|
### 为什么要扰动处理?
|
||||||
|
|
||||||
扰动处理是为了减少哈希冲突,防止哈希值分布不均。HashMap会对哈希值进行扰动处理,以确保不同的键能够更均匀地分布在数组中,从而减少冲突。
|
扰动处理是为了减少哈希冲突,防止哈希值分布不均。HashMap会对哈希值进行扰动处理,以确保不同的键能够更均匀地分布在数组中,从而减少冲突。
|
||||||
|
|
||||||
在Java 8中,HashMap使用了一个扰动函数来优化hash值的分布:
|
在Java 8中,HashMap使用了一个扰动函数来优化hash值的分布:
|
||||||
@@ -83,6 +87,7 @@ static final int hash(Object key) {
|
|||||||
```
|
```
|
||||||
|
|
||||||
这个函数的作用是:
|
这个函数的作用是:
|
||||||
|
|
||||||
1. 首先获取key的hashCode()值
|
1. 首先获取key的hashCode()值
|
||||||
2. 将hashCode的高16位与低16位进行异或运算
|
2. 将hashCode的高16位与低16位进行异或运算
|
||||||
|
|
||||||
@@ -95,18 +100,19 @@ static final int hash(Object key) {
|
|||||||
n是数组的长度,hash是键的哈希值。
|
n是数组的长度,hash是键的哈希值。
|
||||||
|
|
||||||
### 为什么要让HashMap的容量是2的幂次方?
|
### 为什么要让HashMap的容量是2的幂次方?
|
||||||
|
|
||||||
因为当容量是2的幂次方时,`(n-1) & hash`可以快速计算出索引位置,而不需要进行取模运算。
|
因为当容量是2的幂次方时,`(n-1) & hash`可以快速计算出索引位置,而不需要进行取模运算。
|
||||||
|
|
||||||
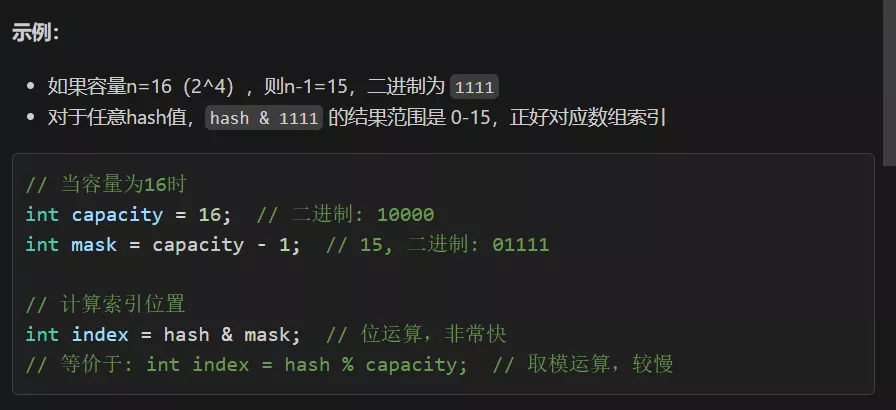
|

|
||||||
|
|
||||||
### 为什么会用到链表?
|
### 为什么会用到链表?
|
||||||
|
|
||||||
我们在HashMap的使用过程中,可能会遇到哈希冲突的情况,也就是不同的键经过哈希函数计算后得到了相同的索引位置,使用链表我们可以把这些冲突的键值对存储在同一个桶中,用链表连接在一起,jdk8开始,链表节点不再使用头插法,而是使用尾插法,这样可以减少链表的长度,提升查找效率。
|
我们在HashMap的使用过程中,可能会遇到哈希冲突的情况,也就是不同的键经过哈希函数计算后得到了相同的索引位置,使用链表我们可以把这些冲突的键值对存储在同一个桶中,用链表连接在一起,jdk8开始,链表节点不再使用头插法,而是使用尾插法,这样可以减少链表的长度,提升查找效率。
|
||||||
|
|
||||||
头插法还可能造成链表形成环形,导致死循环。
|
头插法还可能造成链表形成环形,导致死循环。
|
||||||
|
|
||||||
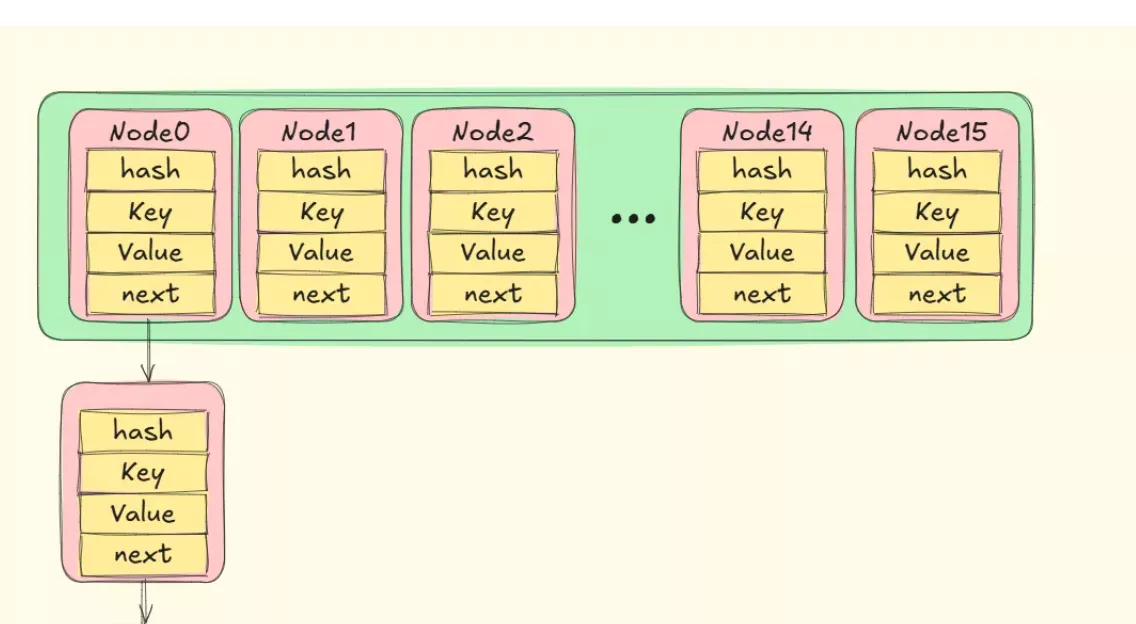
|

|
||||||
|
|
||||||
|
|
||||||
## Node
|
## Node
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@@ -149,9 +155,8 @@ n是数组的长度,hash是键的哈希值。
|
|||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
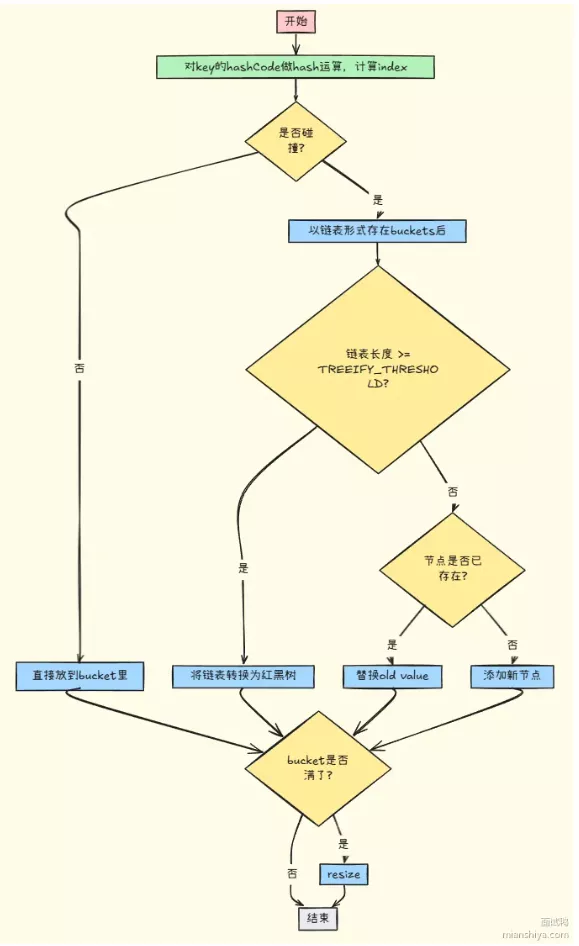
# HashMap的Put方法
|
# HashMap的Put方法
|
||||||
|
|
||||||
HashMap的put方法是用来添加键值对到HashMap中的核心方法。它的实现逻辑如下:
|
HashMap的put方法是用来添加键值对到HashMap中的核心方法。它的实现逻辑如下:
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@@ -237,7 +242,6 @@ HashMap的put方法是用来添加键值对到HashMap中的核心方法。它的
|
|||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|
||||||
# HashMap的Get方法
|
# HashMap的Get方法
|
||||||
|
|
||||||
```java
|
```java
|
||||||
@@ -281,18 +285,17 @@ HashMap的put方法是用来添加键值对到HashMap中的核心方法。它的
|
|||||||
|
|
||||||
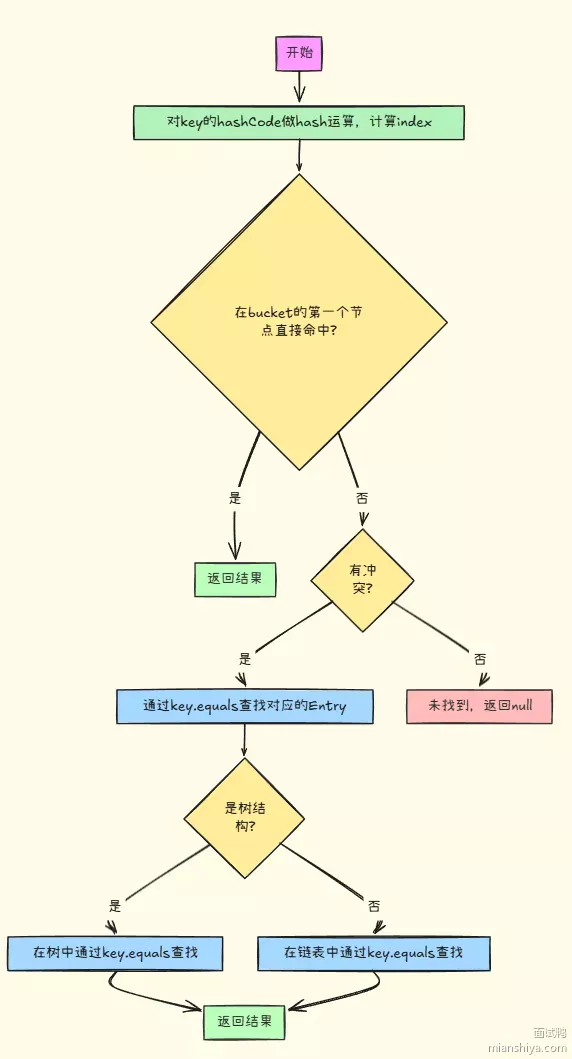
|

|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# HashMap的扩容
|
# HashMap的扩容
|
||||||
|
|
||||||
HashMap的扩容是指当存储的元素数量超过负载因子所允许的最大数量时,HashMap会自动增加其容量。
|
HashMap的扩容是指当存储的元素数量超过负载因子所允许的最大数量时,HashMap会自动增加其容量。
|
||||||
扩容的过程包括以下几个步骤:
|
扩容的过程包括以下几个步骤:
|
||||||
|
|
||||||
1. **计算新的容量**:新的容量通常是当前容量的两倍。
|
1. **计算新的容量**:新的容量通常是当前容量的两倍。
|
||||||
2. **创建新的数组**:创建一个新的数组来存储扩容后的元素。
|
2. **创建新的数组**:创建一个新的数组来存储扩容后的元素。
|
||||||
3. **重新计算索引位置**:对于每个元素,重新计算其在新数组中的索引位置,并将其移动到新数组中。
|
3. **重新计算索引位置**:对于每个元素,重新计算其在新数组中的索引位置,并将其移动到新数组中。
|
||||||
|
|
||||||
源码中是resize()函数
|
源码中是resize()函数
|
||||||
|
|
||||||
|
|
||||||
```java
|
```java
|
||||||
/**
|
/**
|
||||||
* 初始化或将表大小扩大一倍。如果为null,则根据字段threshold中保存的初始容量目标进行分配。
|
* 初始化或将表大小扩大一倍。如果为null,则根据字段threshold中保存的初始容量目标进行分配。
|
||||||
@@ -406,8 +409,8 @@ final Node<K,V>[] resize() { // 📏 定义扩容方法
|
|||||||
}
|
}
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
## 扩容的时候高位和低位链表详解
|
## 扩容的时候高位和低位链表详解
|
||||||
|
|
||||||
```java
|
```java
|
||||||
else {
|
else {
|
||||||
Node<K,V> loHead = null, loTail = null; // 🔻 低位链表的头和尾节点
|
Node<K,V> loHead = null, loTail = null; // 🔻 低位链表的头和尾节点
|
||||||
@@ -454,6 +457,7 @@ else {
|
|||||||
### 核心原理
|
### 核心原理
|
||||||
|
|
||||||
当HashMap从容量n扩容到2n时,每个元素的新位置只有两种可能:
|
当HashMap从容量n扩容到2n时,每个元素的新位置只有两种可能:
|
||||||
|
|
||||||
- **保持原位置**(低位链表)
|
- **保持原位置**(低位链表)
|
||||||
- **移动到原位置+n**(高位链表)
|
- **移动到原位置+n**(高位链表)
|
||||||
|
|
||||||
@@ -463,6 +467,7 @@ else {
|
|||||||
- 高位链表(hi list):满足 `(e.hash & oldCap) != 0` 的节点,扩容后放在新位置 `j + oldCap`。
|
- 高位链表(hi list):满足 `(e.hash & oldCap) != 0` 的节点,扩容后放在新位置 `j + oldCap`。
|
||||||
|
|
||||||
#### 举例子
|
#### 举例子
|
||||||
|
|
||||||
假设oldCap = 16,newCap = 32
|
假设oldCap = 16,newCap = 32
|
||||||
|
|
||||||
oldCap=16 // 10000
|
oldCap=16 // 10000
|
||||||
@@ -492,8 +497,8 @@ hash1 & oldCap ==> 5 & 16
|
|||||||
所以这个kv会放在原位置5
|
所以这个kv会放在原位置5
|
||||||
```
|
```
|
||||||
|
|
||||||
|
|
||||||
再举个例子
|
再举个例子
|
||||||
|
|
||||||
```
|
```
|
||||||
hash2 = 20; // 10100
|
hash2 = 20; // 10100
|
||||||
|
|
||||||
@@ -525,14 +530,14 @@ hash2 & oldCap ==> 20 & 16
|
|||||||
---
|
---
|
||||||
|
|
||||||
### 为什么判断的是与oldCap相与得到的值是1还是0来决定搬迁位置?
|
### 为什么判断的是与oldCap相与得到的值是1还是0来决定搬迁位置?
|
||||||
当HashMap扩容时,容量从 `oldCap` 扩展到 `newCap`,比如从 16 扩展到 32。
|
|
||||||
|
|
||||||
|
当HashMap扩容时,容量从 `oldCap` 扩展到 `newCap`,比如从 16 扩展到 32。
|
||||||
|
|
||||||
- 原来 HashMap 的下标计算是:`index = hash & (oldCap-1)`,比如 `00001111`(低4位)。
|
- 原来 HashMap 的下标计算是:`index = hash & (oldCap-1)`,比如 `00001111`(低4位)。
|
||||||
- 扩容后,计算下标变为:`index = hash & (newCap-1)`,比如 `00011111`(低5位),也就是多了一位。
|
- 扩容后,计算下标变为:`index = hash & (newCap-1)`,比如 `00011111`(低5位),也就是多了一位。
|
||||||
- 和 `oldCap`(如 `00010000`)相与,就相当于“掐头去尾”地只关注扩容新增的那一位:
|
- 和 `oldCap`(如 `00010000`)相与,就相当于“掐头去尾”地只关注扩容新增的那一位:
|
||||||
- 如果 `(hash & oldCap) == 0`,说明这位是0,**扩容后的位置等于原index**
|
- 如果 `(hash & oldCap) == 0`,说明这位是0,**扩容后的位置等于原index**
|
||||||
- 如果 `(hash & oldCap) != 0`,说明这位是1,**扩容后的位置等于原index + oldCap**
|
- 如果 `(hash & oldCap) != 0`,说明这位是1,**扩容后的位置等于原index + oldCap**
|
||||||
- 这种判断,让你高效知道节点该不该搬迁以及搬去哪里,无需重新完全计算index。
|
- 这种判断,让你高效知道节点该不该搬迁以及搬去哪里,无需重新完全计算index。
|
||||||
|
|
||||||
---
|
---
|
||||||
@@ -540,6 +545,7 @@ hash2 & oldCap ==> 20 & 16
|
|||||||
#### 举例验证(巩固印象)
|
#### 举例验证(巩固印象)
|
||||||
|
|
||||||
假如:
|
假如:
|
||||||
|
|
||||||
- oldCap = 16 ⇒ 00010000
|
- oldCap = 16 ⇒ 00010000
|
||||||
- oldCap-1 = 15 ⇒ 00001111
|
- oldCap-1 = 15 ⇒ 00001111
|
||||||
- newCap = 32 ⇒ 00100000
|
- newCap = 32 ⇒ 00100000
|
||||||
@@ -547,27 +553,32 @@ hash2 & oldCap ==> 20 & 16
|
|||||||
- hash = 21 ⇒ 10101
|
- hash = 21 ⇒ 10101
|
||||||
|
|
||||||
**扩容前下标:**
|
**扩容前下标:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
index = 10101 & 01111 = 00101 = 5
|
index = 10101 & 01111 = 00101 = 5
|
||||||
```
|
```
|
||||||
|
|
||||||
**扩容后下标:**
|
**扩容后下标:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
index = 10101 & 11111 = 10101 = 21
|
index = 10101 & 11111 = 10101 = 21
|
||||||
```
|
```
|
||||||
|
|
||||||
**oldCap这一位的判断:**
|
**oldCap这一位的判断:**
|
||||||
|
|
||||||
```java
|
```java
|
||||||
10101 & 10000 = 10000 ≠ 0
|
10101 & 10000 = 10000 ≠ 0
|
||||||
```
|
```
|
||||||
|
|
||||||
说明这位是1,扩容后下标变成原index+16=21。
|
说明这位是1,扩容后下标变成原index+16=21。
|
||||||
|
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
### 扩容的条件是什么?
|
### 扩容的条件是什么?
|
||||||
|
|
||||||
当 HashMap 中存储的元素数量超过了「阈值」(threshold)时,就会进行扩容。
|
当 HashMap 中存储的元素数量超过了「阈值」(threshold)时,就会进行扩容。
|
||||||
这个「阈值」的计算公式是:
|
这个「阈值」的计算公式是:
|
||||||
|
|
||||||
```
|
```
|
||||||
threshold = capacity * loadFactor
|
threshold = capacity * loadFactor
|
||||||
```
|
```
|
||||||
@@ -580,9 +591,8 @@ HashMap扩容的主要目的是:
|
|||||||
减少哈希冲突,提高查找、插入效率。
|
减少哈希冲突,提高查找、插入效率。
|
||||||
让更多桶可用,降低碰撞链表队列的长度。
|
让更多桶可用,降低碰撞链表队列的长度。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
# jdk1.7和jdk1.8中hashmap的区别
|
# jdk1.7和jdk1.8中hashmap的区别
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||

|

|
||||||
@@ -593,9 +603,8 @@ HashMap扩容的主要目的是:
|
|||||||
|
|
||||||

|

|
||||||
|
|
||||||
|
|
||||||
# 链表什么时候转红黑树?
|
# 链表什么时候转红黑树?
|
||||||
|
|
||||||
桶数组中某个桶的链表长度>=8 而且桶数组长度> 64的时候,hashmap会转换为红黑树
|
桶数组中某个桶的链表长度>=8 而且桶数组长度> 64的时候,hashmap会转换为红黑树
|
||||||
|
|
||||||

|

|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [mysql锁]
|
tags: [mysql锁]
|
||||||
category: 'MySQL'
|
category: '中间件 > MySQL'
|
||||||
draft: false
|
draft: false
|
||||||
lang: 'zh-cn'
|
lang: 'zh-cn'
|
||||||
---
|
---
|
||||||
@@ -217,4 +217,3 @@ COMMIT;
|
|||||||
### 总结
|
### 总结
|
||||||
|
|
||||||
MySQL的排他锁是确保数据写操作一致性的重要机制,广泛用于事务性操作。通过合理设计查询和事务,可以最大程度减少锁冲突和性能问题。在高并发场景下,建议结合索引优化、事务管理以及合适的隔离级别来平衡一致性和性能。
|
MySQL的排他锁是确保数据写操作一致性的重要机制,广泛用于事务性操作。通过合理设计查询和事务,可以最大程度减少锁冲突和性能问题。在高并发场景下,建议结合索引优化、事务管理以及合适的隔离级别来平衡一致性和性能。
|
||||||
|
|
||||||
@@ -4,7 +4,7 @@ published: 2025-07-18
|
|||||||
description: ''
|
description: ''
|
||||||
image: ''
|
image: ''
|
||||||
tags: [Nginx编译安装]
|
tags: [Nginx编译安装]
|
||||||
category: 'Nginx'
|
category: '中间件 > Nginx'
|
||||||
draft: false
|
draft: false
|
||||||
lang: 'zh-cn'
|
lang: 'zh-cn'
|
||||||
---
|
---
|
||||||
@@ -39,4 +39,3 @@ make
|
|||||||
make install
|
make install
|
||||||
|
|
||||||
```
|
```
|
||||||
|
|
||||||
23
src/content/posts/中间件/nacos/nacos安装.md
Normal file
23
src/content/posts/中间件/nacos/nacos安装.md
Normal file
@@ -0,0 +1,23 @@
|
|||||||
|
---
|
||||||
|
title: nacos安装
|
||||||
|
published: 2025-07-19
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [nacos, 中间件, 安装]
|
||||||
|
category: '中间件 > Nacos'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
# nacos安装
|
||||||
|
|
||||||
|
```
|
||||||
|
docker run --name nacos-standalone-derby \
|
||||||
|
-e MODE=standalone \
|
||||||
|
-e NACOS_AUTH_TOKEN=bWVvd3JhaW55eWRzNjY2Nm1lb3dyYWlueXlkczY2NjY= \
|
||||||
|
-e NACOS_AUTH_IDENTITY_KEY=meowrain \
|
||||||
|
-e NACOS_AUTH_IDENTITY_VALUE=meowrain \
|
||||||
|
-p 8085:8080 \
|
||||||
|
-p 8848:8848 \
|
||||||
|
-p 9848:9848 \
|
||||||
|
-d nacos/nacos-server:latest
|
||||||
|
```
|
||||||
455
src/content/posts/数据结构与算法/TrieMap实现.md
Normal file
455
src/content/posts/数据结构与算法/TrieMap实现.md
Normal file
@@ -0,0 +1,455 @@
|
|||||||
|
---
|
||||||
|
title: TrieMap实现
|
||||||
|
published: 2025-07-19
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [TrieMap, 数据结构, 算法]
|
||||||
|
category: '数据结构与算法'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
|
||||||
|
<https://labuladong.online/algo/data-structure/trie-implement/#trieset-%E7%9A%84%E5%AE%9E%E7%8E%B0>
|
||||||
|
|
||||||
|
<https://labuladong.online/algo/data-structure-basic/trie-map-basic/>
|
||||||
|
**TrieMap 是什么?**
|
||||||
|
Tire树又称字典树/前缀树,具有如下特点
|
||||||
|
|
||||||
|
根节点不包含字符 除根节点外每个节点只包含一个字符
|
||||||
|
树的每一个路径都是一个字符串
|
||||||
|
每个节点的子节点包含的字符都不相同
|
||||||
|
|
||||||
|
简单来说,**TrieMap 就是一个将 Trie(前缀树)的数据结构与 Map(映射)的功能结合起来的集合。** 它不仅仅是一个键值对的存储器,更是一个能够高效地处理与字符串(或任何序列)键相关的各种操作的强大工具。
|
||||||
|
|
||||||
|
**核心思想:Trie + Map**
|
||||||
|
|
||||||
|
1. **Trie(前缀树)作为底层结构:**
|
||||||
|
* Trie 的核心思想是利用键的公共前缀来共享节点,从而节省空间和提高查找效率。
|
||||||
|
* 每个节点通常代表键的一个字符或序列中的一个元素。
|
||||||
|
* 从根节点到任意一个节点的路径,代表了一个前缀。
|
||||||
|
|
||||||
|
2. **Map 的功能扩展:**
|
||||||
|
* 在 Trie 的基础上,将值 "挂载" 到 Trie 的特定节点上。
|
||||||
|
* 通常,当一个键的完整路径在一个 Trie 节点处结束时,这个节点会包含与该键关联的值。
|
||||||
|
* 一个节点可以有多个子节点(对应不同的下一个字符),也可以存储一个值(表示该前缀本身就是一个完整的键)。
|
||||||
|
|
||||||
|
**TrieMap 的结构和工作原理**
|
||||||
|
|
||||||
|
* **节点(Node):** TrieMap 的基本构建单元。每个节点至少包含:
|
||||||
|
* **子节点指针(Children):** 通常是一个 Map 或数组,用于存储指向下一个字符/元素的子节点的引用。例如,`Map<Character, Node>` 或 `Node[26]` (针对英文字母)。
|
||||||
|
* **值(Value):** 一个可选的字段,如果当前节点代表一个完整的键的结束,则该字段存储与该键关联的值。如果一个节点只是一个前缀,但不是一个完整的键,则此字段可能为 `null` 或表示没有值。
|
||||||
|
* **isEndOfWord/isKey (布尔值):** 一个标记,指示当前节点是否代表一个完整的键的结束。这在区分一个前缀 vs. 一个完整的键时非常有用。
|
||||||
|
|
||||||
|
* **插入(`put(key, value)`):**
|
||||||
|
1. 从根节点开始。
|
||||||
|
2. 遍历键的每个字符。对于每个字符:
|
||||||
|
* 如果当前节点的子节点中已经存在指向该字符的节点,则移动到该子节点。
|
||||||
|
* 如果不存在,则创建一个新的子节点,并将其添加到当前节点的子节点集合中,然后移动到新创建的节点。
|
||||||
|
3. 当遍历完所有字符后,到达最终节点。将该节点的 `value` 字段设置为传入的 `value`,并设置 `isEndOfWord` 为 `true`。
|
||||||
|
|
||||||
|
* **查找(`get(key)`):**
|
||||||
|
1. 从根节点开始。
|
||||||
|
2. 遍历键的每个字符。对于每个字符:
|
||||||
|
* 如果当前节点的子节点中不存在指向该字符的节点,则说明键不存在,返回 `null`。
|
||||||
|
* 如果存在,则移动到该子节点。
|
||||||
|
3. 当遍历完所有字符后,到达最终节点。检查该节点的 `isEndOfWord` 标记。如果为 `true`,则返回该节点的 `value`;否则(如果只是一个前缀),返回 `null`。
|
||||||
|
|
||||||
|
* **删除(`remove(key)`):**
|
||||||
|
删除操作相对复杂,需要考虑:
|
||||||
|
1. 找到键对应的最终节点。
|
||||||
|
2. 将该节点的 `value` 设置为 `null`,并 `isEndOfWord` 设置为 `false`(逻辑删除)。
|
||||||
|
3. 如果删除后,该节点不再是任何其他键的前缀,并且也没有任何子节点,那么它可以从树中物理删除,需要回溯父节点并移除指向它的引用,一直回溯到第一个有其他作用(是其他键的前缀或有其他子节点)的节点。这通常需要递归实现。
|
||||||
|
|
||||||
|
**TrieMap 的特性和优势**
|
||||||
|
|
||||||
|
1. **高效的前缀匹配和查找:**
|
||||||
|
* **查找时间复杂度:O(L)**,其中 L 是键的长度。这比基于哈希表的 Map 在最坏情况下(哈希冲突严重)的 O(L) 或 O(N) 性能更好,而且在平均情况下哈希表是 O(1),但 TrieMap 在键长较短时表现出色,且无哈希冲突问题。
|
||||||
|
* 特别适合**“前缀搜索”**或**“自动补全”**:可以直接遍历一个前缀对应的节点及其所有子树,找到所有以该前缀开头的键。
|
||||||
|
|
||||||
|
2. **空间效率(部分情况下):**
|
||||||
|
* 当键之间有大量公共前缀时,可以显著节省空间,因为共享了节点。
|
||||||
|
* 然而,如果键之间前缀很少,或者键的字符集非常大,每个节点有大量子节点指针,那么空间开销可能会比 HashMap 大。
|
||||||
|
|
||||||
|
3. **有序性(基于键的前缀):**
|
||||||
|
虽然不是像 TreeMap 那样按键的整体排序,但 TrieMap 在结构上体现了键的前缀有序性,这使得前缀相关的操作非常自然和高效。
|
||||||
|
|
||||||
|
4. **键可以是任意序列:**
|
||||||
|
尽管最常见的是字符串,但只要能定义元素的顺序和比较,键可以是任何序列(例如,字节数组,整数数组)。
|
||||||
|
|
||||||
|
**TrieMap 的应用场景**
|
||||||
|
|
||||||
|
* **自动补全/拼写检查:** 用户输入时,快速提供以当前输入为前缀的建议词汇。
|
||||||
|
* **路由表:** 网络路由器可以使用 Trie 来存储 IP 地址或网络前缀,从而快速查找匹配的路由规则。
|
||||||
|
* **词典/字典树:** 存储大量词汇,进行快速查找、前缀匹配等操作。
|
||||||
|
* **IP 地址查找:** 查找某个 IP 地址是否在某个大的网段中。
|
||||||
|
* **DNS 解析:** 查找域名对应的 IP 地址。
|
||||||
|
* **文本搜索匹配:** 在文本中查找特定模式。
|
||||||
|
* **数据压缩:** 通过共享前缀来降低存储冗余。
|
||||||
|
|
||||||
|
**TrieMap 的潜在缺点**
|
||||||
|
|
||||||
|
* **空间开销:** 如果键的前缀共享不多,或者键的字符集很大(导致每个节点子节点Map/数组大而稀疏),空间效率可能不高。
|
||||||
|
* **实现复杂度:** 相对于 HashMap,实现 TrieMap 更复杂,尤其是删除操作。
|
||||||
|
* **非随机访问:** 无法像数组那样通过索引直接访问,访问任何一个键都需要从根节点遍历到对应节点。
|
||||||
|
|
||||||
|
**与 HashMap/TreeMap 的比较**
|
||||||
|
|
||||||
|
* **HashMap:** 最佳平均时间复杂度 O(1) 用于 `get`, `put`。不保证键的顺序。不擅长前缀搜索。
|
||||||
|
* **TreeMap:** 基于红黑树实现,所有操作都是 O(log N)。键是排序的。支持范围查询,但前缀搜索不如 TrieMap 直观和高效。
|
||||||
|
* **TrieMap:** 最佳时间复杂度 O(L) (键长)。特别擅长前缀搜索及自动补全。在大量键有公共前缀时空间效率高。
|
||||||
|
|
||||||
|
**总结**
|
||||||
|
|
||||||
|
TrieMap 是一种非常有用且强大的数据结构,它利用前缀树的特性,在处理字符串(或其他序列)键的映射和前缀相关操作时展现出卓越的性能。理解其节点结构和操作原理是掌握它的关键。在需要高效前缀搜索和存储大量相关键的场景下,TrieMap 是一个值得考虑的优秀选择。
|
||||||
|
|
||||||
|
```go
|
||||||
|
package trie_map
|
||||||
|
|
||||||
|
// TrieNode 表示字典树中的一个节点,包含可选值和子节点指针数组
|
||||||
|
type TrieNode[T any] struct {
|
||||||
|
val *T // 节点存储的值,如果为 nil 表示不是一个完整 key
|
||||||
|
children []*TrieNode[T] // 子节点数组,长度为字符集大小 R
|
||||||
|
}
|
||||||
|
|
||||||
|
// NewTrieNode 创建一个新的 TrieNode,初始化子节点数组长度为 R
|
||||||
|
func NewTrieNode[T any](R int) *TrieNode[T] {
|
||||||
|
return &TrieNode[T]{
|
||||||
|
children: make([]*TrieNode[T], R), // 初始化长度为 R 的子节点数组
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// TrieMap 是一个基于 Trie 的映射结构,支持字符串键和值的泛型映射
|
||||||
|
type TrieMap[T any] struct {
|
||||||
|
R int // 字符集大小,例如 256 表示 ASCII 字符集
|
||||||
|
size int // 当前存储的键值对数量
|
||||||
|
root *TrieNode[T] // Trie 树的根节点
|
||||||
|
}
|
||||||
|
|
||||||
|
// NewTrieMap 创建一个空的 TrieMap,使用默认的 ASCII 字符集大小 256
|
||||||
|
func NewTrieMap[T any]() *TrieMap[T] {
|
||||||
|
trieMap := &TrieMap[T]{
|
||||||
|
size: 0,
|
||||||
|
R: 256, // 默认支持 ASCII 范围内的字符
|
||||||
|
}
|
||||||
|
trieMap.root = NewTrieNode[T](trieMap.R) // 初始化根节点
|
||||||
|
return trieMap
|
||||||
|
}
|
||||||
|
|
||||||
|
// Size 返回 TrieMap 中键值对的数量
|
||||||
|
func (tm *TrieMap[T]) Size() int {
|
||||||
|
return tm.size
|
||||||
|
}
|
||||||
|
|
||||||
|
// GetNode 查找 key 对应的终止节点(若存在)
|
||||||
|
func GetNode[T any](node *TrieNode[T], key string) *TrieNode[T] {
|
||||||
|
if node == nil {
|
||||||
|
return nil
|
||||||
|
}
|
||||||
|
p := node
|
||||||
|
for i := 0; i < len(key); i++ {
|
||||||
|
if p == nil {
|
||||||
|
return nil
|
||||||
|
}
|
||||||
|
var c byte = key[i]
|
||||||
|
p = p.children[c] // 向下查找子节点
|
||||||
|
}
|
||||||
|
return p
|
||||||
|
}
|
||||||
|
|
||||||
|
// Get 返回 key 对应的值指针,若不存在则返回 nil
|
||||||
|
func (tm *TrieMap[T]) Get(key string) *T {
|
||||||
|
node := GetNode(tm.root, key)
|
||||||
|
if node == nil || node.val == nil {
|
||||||
|
return nil
|
||||||
|
}
|
||||||
|
return node.val
|
||||||
|
}
|
||||||
|
|
||||||
|
// ContainsKey 判断是否存在指定 key
|
||||||
|
func (tm *TrieMap[T]) ContainsKey(key string) bool {
|
||||||
|
return tm.Get(key) != nil
|
||||||
|
}
|
||||||
|
|
||||||
|
// HasKeyWithPrefix 判断是否存在某个以 prefix 为前缀的 key
|
||||||
|
func (tm *TrieMap[T]) HasKeyWithPrefix(prefix string) bool {
|
||||||
|
return GetNode(tm.root, prefix) != nil
|
||||||
|
}
|
||||||
|
|
||||||
|
// ShortestPrefixOf 查找 query 的最短前缀,该前缀在 TrieMap 中存在
|
||||||
|
func (tm *TrieMap[T]) ShortestPrefixOf(query string) string {
|
||||||
|
p := tm.root
|
||||||
|
for i := 0; i < len(query); i++ {
|
||||||
|
if p == nil {
|
||||||
|
break
|
||||||
|
}
|
||||||
|
if p.val != nil {
|
||||||
|
return query[:i] // 找到前缀匹配
|
||||||
|
}
|
||||||
|
var c byte = query[i]
|
||||||
|
p = p.children[c]
|
||||||
|
}
|
||||||
|
if p != nil && p.val != nil {
|
||||||
|
return query // 整个 query 是前缀
|
||||||
|
}
|
||||||
|
return "" // 没有任何前缀匹配
|
||||||
|
}
|
||||||
|
|
||||||
|
// LongestPrefixOf 查找 query 的最长前缀,该前缀在 TrieMap 中存在
|
||||||
|
func (tm *TrieMap[T]) LongestPrefixOf(query string) string {
|
||||||
|
node := tm.root
|
||||||
|
max_len := 0
|
||||||
|
for i := 0; i < len(query); i++ {
|
||||||
|
if node == nil {
|
||||||
|
break
|
||||||
|
}
|
||||||
|
if node.val != nil {
|
||||||
|
max_len = i
|
||||||
|
}
|
||||||
|
var c byte = query[i]
|
||||||
|
node = node.children[c]
|
||||||
|
}
|
||||||
|
if node != nil && node.val != nil {
|
||||||
|
return query // 整个 query 是匹配项
|
||||||
|
}
|
||||||
|
return query[:max_len] // 返回最长匹配前缀
|
||||||
|
}
|
||||||
|
|
||||||
|
// KeysWithPrefix 返回所有以 prefix 开头的键
|
||||||
|
func (tm *TrieMap[T]) KeysWithPrefix(prefix string) []string {
|
||||||
|
var keys []string = make([]string, 0)
|
||||||
|
node := GetNode[T](tm.root, prefix)
|
||||||
|
if node == nil {
|
||||||
|
return keys // 没有该前缀
|
||||||
|
}
|
||||||
|
tm.traverseForKeysWithPrefix(node, prefix, &keys)
|
||||||
|
return keys
|
||||||
|
}
|
||||||
|
|
||||||
|
// traverseForKeysWithPrefix 递归收集所有以当前路径为前缀的 key
|
||||||
|
func (tm *TrieMap[T]) traverseForKeysWithPrefix(node *TrieNode[T], currentPath string, res *[]string) {
|
||||||
|
if node == nil {
|
||||||
|
return
|
||||||
|
}
|
||||||
|
if node.val != nil {
|
||||||
|
*res = append(*res, currentPath) // 找到一个完整 key
|
||||||
|
}
|
||||||
|
for i := 0; i < tm.R; i++ {
|
||||||
|
currentPath = currentPath + string(byte(i))
|
||||||
|
tm.traverseForKeysWithPrefix(node.children[i], currentPath, res)
|
||||||
|
currentPath = currentPath[:len(currentPath)-1] // 回溯
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// KeysWithPattern 查找所有匹配模式的 key,支持通配符 '.'
|
||||||
|
func (tm *TrieMap[T]) KeysWithPattern(pattern string) []string {
|
||||||
|
var keys []string = make([]string, 0)
|
||||||
|
tm.traverseForKeysWithPattern(tm.root, "", pattern, 0, &keys)
|
||||||
|
return keys
|
||||||
|
}
|
||||||
|
|
||||||
|
// traverseForKeysWithPattern 回溯遍历支持通配符的模式匹配
|
||||||
|
func (tm *TrieMap[T]) traverseForKeysWithPattern(node *TrieNode[T], path string, pattern string, i int, keys *[]string) {
|
||||||
|
if node == nil {
|
||||||
|
return
|
||||||
|
}
|
||||||
|
if i == len(pattern) {
|
||||||
|
if node.val != nil {
|
||||||
|
*keys = append(*keys, path)
|
||||||
|
}
|
||||||
|
return
|
||||||
|
}
|
||||||
|
c := pattern[i]
|
||||||
|
if c == '.' {
|
||||||
|
for j := 0; j < tm.R; j++ {
|
||||||
|
path = path + string(byte(j))
|
||||||
|
tm.traverseForKeysWithPattern(node.children[j], path, pattern, i+1, keys)
|
||||||
|
path = path[:len(path)-1]
|
||||||
|
}
|
||||||
|
} else {
|
||||||
|
path = path + string(byte(c))
|
||||||
|
tm.traverseForKeysWithPattern(node.children[c], path, pattern, i+1, keys)
|
||||||
|
path = path[:len(path)-1]
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// HasKeyWithPattern 判断是否存在匹配指定模式的 key
|
||||||
|
func (tm *TrieMap[T]) HasKeyWithPattern(pattern string) bool {
|
||||||
|
return len(tm.KeysWithPattern(pattern)) > 0
|
||||||
|
}
|
||||||
|
|
||||||
|
// Put 插入或更新 key 对应的值
|
||||||
|
func (tm *TrieMap[T]) Put(key string, v T) {
|
||||||
|
if !tm.ContainsKey(key) {
|
||||||
|
tm.size++ // 是新增 key
|
||||||
|
}
|
||||||
|
tm.root = tm.putNode(tm.root, key, &v, 0)
|
||||||
|
}
|
||||||
|
|
||||||
|
// putNode 递归构建节点路径,直到 key 的末尾
|
||||||
|
func (tm *TrieMap[T]) putNode(node *TrieNode[T], key string, val *T, i int) *TrieNode[T] {
|
||||||
|
if node == nil {
|
||||||
|
node = NewTrieNode[T](tm.R)
|
||||||
|
}
|
||||||
|
if i == len(key) {
|
||||||
|
node.val = val // 在最后一个节点上存储值
|
||||||
|
return node
|
||||||
|
}
|
||||||
|
c := key[i]
|
||||||
|
node.children[c] = tm.putNode(node.children[c], key, val, i+1)
|
||||||
|
return node
|
||||||
|
}
|
||||||
|
|
||||||
|
// Remove 从 TrieMap 中删除 key
|
||||||
|
func (tm *TrieMap[T]) Remove(key string) {
|
||||||
|
if !tm.ContainsKey(key) {
|
||||||
|
return // key 不存在
|
||||||
|
}
|
||||||
|
tm.root = tm.removeNode(tm.root, key, 0)
|
||||||
|
tm.size--
|
||||||
|
}
|
||||||
|
|
||||||
|
// removeNode 删除 key 路径上的值,必要时清除无用节点
|
||||||
|
func (tm *TrieMap[T]) removeNode(node *TrieNode[T], key string, i int) *TrieNode[T] {
|
||||||
|
if node == nil {
|
||||||
|
return nil
|
||||||
|
}
|
||||||
|
if i == len(key) {
|
||||||
|
node.val = nil // 删除节点值
|
||||||
|
} else {
|
||||||
|
c := key[i]
|
||||||
|
node.children[c] = tm.removeNode(node.children[c], key, i+1)
|
||||||
|
}
|
||||||
|
if node.val != nil {
|
||||||
|
return node
|
||||||
|
}
|
||||||
|
for i := 0; i < tm.R; i++ {
|
||||||
|
if node.children[i] != nil {
|
||||||
|
return node // 有孩子不能删除
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return nil // 无值无子,删除此节点
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
---
|
||||||
|
|
||||||
|
```go
|
||||||
|
package trie_map
|
||||||
|
|
||||||
|
import (
|
||||||
|
"reflect"
|
||||||
|
"testing"
|
||||||
|
)
|
||||||
|
|
||||||
|
func TestTrieMap_BasicOperations(t *testing.T) {
|
||||||
|
trie := NewTrieMap[int]()
|
||||||
|
|
||||||
|
// Test Put and Get
|
||||||
|
trie.Put("apple", 100)
|
||||||
|
trie.Put("app", 200)
|
||||||
|
trie.Put("banana", 300)
|
||||||
|
|
||||||
|
if v := trie.Get("apple"); v == nil || *v != 100 {
|
||||||
|
t.Errorf("expected 100, got %v", v)
|
||||||
|
}
|
||||||
|
|
||||||
|
if v := trie.Get("app"); v == nil || *v != 200 {
|
||||||
|
t.Errorf("expected 200, got %v", v)
|
||||||
|
}
|
||||||
|
|
||||||
|
if v := trie.Get("banana"); v == nil || *v != 300 {
|
||||||
|
t.Errorf("expected 300, got %v", v)
|
||||||
|
}
|
||||||
|
|
||||||
|
if v := trie.Get("unknown"); v != nil {
|
||||||
|
t.Errorf("expected nil for unknown key, got %v", *v)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test ContainsKey
|
||||||
|
if !trie.ContainsKey("apple") {
|
||||||
|
t.Error("expected ContainsKey(\"apple\") to be true")
|
||||||
|
}
|
||||||
|
|
||||||
|
if trie.ContainsKey("unknown") {
|
||||||
|
t.Error("expected ContainsKey(\"unknown\") to be false")
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test Size
|
||||||
|
if size := trie.Size(); size != 3 {
|
||||||
|
t.Errorf("expected size 3, got %d", size)
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func TestTrieMap_PrefixAndPattern(t *testing.T) {
|
||||||
|
trie := NewTrieMap[int]()
|
||||||
|
trie.Put("apple", 1)
|
||||||
|
trie.Put("app", 2)
|
||||||
|
trie.Put("apricot", 3)
|
||||||
|
trie.Put("bat", 4)
|
||||||
|
trie.Put("ball", 5)
|
||||||
|
|
||||||
|
// Test KeysWithPrefix
|
||||||
|
prefixKeys := trie.KeysWithPrefix("ap")
|
||||||
|
expected := []string{"app", "apple", "apricot"}
|
||||||
|
if !reflect.DeepEqual(stringSet(prefixKeys), stringSet(expected)) {
|
||||||
|
t.Errorf("KeysWithPrefix failed, got %v, expected %v", prefixKeys, expected)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test ShortestPrefixOf
|
||||||
|
query := "applepie"
|
||||||
|
shortest := trie.ShortestPrefixOf(query)
|
||||||
|
if shortest != "app" {
|
||||||
|
t.Errorf("expected shortest prefix to be 'app', got %s", shortest)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test LongestPrefixOf
|
||||||
|
longest := trie.LongestPrefixOf(query)
|
||||||
|
if longest != "apple" {
|
||||||
|
t.Errorf("expected longest prefix to be 'apple', got %s", longest)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test KeysWithPattern
|
||||||
|
trie.Put("bake", 6)
|
||||||
|
patternKeys := trie.KeysWithPattern("ba..")
|
||||||
|
expectedPattern := []string{"ball", "bake"}
|
||||||
|
if !reflect.DeepEqual(stringSet(patternKeys), stringSet(expectedPattern)) {
|
||||||
|
t.Errorf("KeysWithPattern failed, got %v, expected %v", patternKeys, expectedPattern)
|
||||||
|
}
|
||||||
|
|
||||||
|
// Test HasKeyWithPattern
|
||||||
|
if !trie.HasKeyWithPattern("b.ll") {
|
||||||
|
t.Error("expected HasKeyWithPattern(\"b.ll\") to be true")
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
func TestTrieMap_Remove(t *testing.T) {
|
||||||
|
trie := NewTrieMap[int]()
|
||||||
|
trie.Put("dog", 10)
|
||||||
|
trie.Put("dot", 20)
|
||||||
|
|
||||||
|
trie.Remove("dog")
|
||||||
|
if trie.ContainsKey("dog") {
|
||||||
|
t.Error("expected 'dog' to be removed")
|
||||||
|
}
|
||||||
|
|
||||||
|
if trie.Size() != 1 {
|
||||||
|
t.Errorf("expected size to be 1 after removal, got %d", trie.Size())
|
||||||
|
}
|
||||||
|
|
||||||
|
// remove nonexistent
|
||||||
|
trie.Remove("notfound")
|
||||||
|
if trie.Size() != 1 {
|
||||||
|
t.Error("removing nonexistent key should not change size")
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
// Helper: make order-insensitive string slice comparison
|
||||||
|
func stringSet(list []string) map[string]struct{} {
|
||||||
|
set := make(map[string]struct{})
|
||||||
|
for _, s := range list {
|
||||||
|
set[s] = struct{}{}
|
||||||
|
}
|
||||||
|
return set
|
||||||
|
}
|
||||||
|
```
|
||||||
361
src/content/posts/设计模式/策略模式.md
Normal file
361
src/content/posts/设计模式/策略模式.md
Normal file
@@ -0,0 +1,361 @@
|
|||||||
|
---
|
||||||
|
title: 策略模式
|
||||||
|
published: 2025-07-19
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [策略模式, 设计模式]
|
||||||
|
category: '设计模式'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
|
||||||
|
# 介绍
|
||||||
|
|
||||||
|
策略模式是一种行为型设计模式。
|
||||||
|
|
||||||
|
在策略模式定义了一系列算法或策略,并将每个算法封装在独立的类中,使得它们可以互相替换。通过使用策略模式,可以在运行时根据需要选择不同的算法,而不需要修改客户端代码。
|
||||||
|
|
||||||
|
在策略模式中,我们创建表示各种策略的对象和一个行为随着策略对象改变而改变的 context 对象。策略对象改变 context 对象的执行算法。
|
||||||
|
|
||||||
|
策略模式平常我们多用来消除if-else switch等多重判断的代码,可以有效地应对代码复杂性。
|
||||||
|
|
||||||
|
下述代码对应的业务,根据对应的优惠类型,对价格作出相应的优惠。
|
||||||
|
|
||||||
|
```java
|
||||||
|
package cn.meowrain;
|
||||||
|
|
||||||
|
import java.util.Objects;
|
||||||
|
|
||||||
|
public class DiscountTest {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
Double result = DiscountTest.discount("1", 100.00);
|
||||||
|
System.out.println(result);
|
||||||
|
}
|
||||||
|
|
||||||
|
public static Double discount(String type, Double price) {
|
||||||
|
if (Objects.equals(type, "1")) {
|
||||||
|
return price * 0.8;
|
||||||
|
} else if (Objects.equals(type, "2")) {
|
||||||
|
return price * 0.6;
|
||||||
|
} else if (Objects.equals(type, "3")) {
|
||||||
|
return price * 0.5;
|
||||||
|
} else {
|
||||||
|
return price;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
> 但是我们很快就能发现问题了,这还是个案例,if else代码块就这么多了,真实的业务会多少if else可想而知了
|
||||||
|
|
||||||
|
我们可以应用策略模式解决这个问题:
|
||||||
|
1.将不同的优惠类型定义为不同的策略算法实现类。
|
||||||
|
2. 保证开闭原则,增加程序的健壮性以及可扩展性。
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
```java
|
||||||
|
package cn.meowrain;
|
||||||
|
|
||||||
|
import java.util.HashMap;
|
||||||
|
import java.util.Map;
|
||||||
|
|
||||||
|
interface DiscountStrategy {
|
||||||
|
Double discount(Double price);
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Implements 80% discount logic.
|
||||||
|
*/
|
||||||
|
class Discount80Strategy implements DiscountStrategy {
|
||||||
|
static {
|
||||||
|
DiscountStrategyFactory.registry("1", new Discount80Strategy());
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public Double discount(Double price) {
|
||||||
|
return price * 0.8; // Bug 1: Incorrect operator `_0.8`
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Implements 60% discount logic.
|
||||||
|
*/
|
||||||
|
class Discount60Strategy implements DiscountStrategy {
|
||||||
|
static {
|
||||||
|
DiscountStrategyFactory.registry("2", new Discount60Strategy());
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public Double discount(Double price) {
|
||||||
|
return price * 0.6; // Bug 2: Incorrect operator `_ 0.6`
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
/**
|
||||||
|
* Implements 50% discount logic.
|
||||||
|
*/
|
||||||
|
class Discount50Strategy implements DiscountStrategy {
|
||||||
|
static {
|
||||||
|
DiscountStrategyFactory.registry("3", new Discount50Strategy());
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public Double discount(Double price) {
|
||||||
|
return price * 0.5;
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
class DiscountStrategyFactory {
|
||||||
|
private static final Map<String, DiscountStrategy> strategyMap = new HashMap<>();
|
||||||
|
|
||||||
|
public static void registry(String type, DiscountStrategy strategy) {
|
||||||
|
strategyMap.put(type, strategy);
|
||||||
|
}
|
||||||
|
|
||||||
|
public static DiscountStrategy getStrategy(String type) {
|
||||||
|
return strategyMap.get(type);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
public class DiscountTest2 {
|
||||||
|
public static void main(String[] args) {
|
||||||
|
new Discount80Strategy();
|
||||||
|
new Discount60Strategy();
|
||||||
|
new Discount50Strategy();
|
||||||
|
Double result1 = DiscountStrategyFactory.getStrategy("1").discount(100.00);
|
||||||
|
System.out.println("80% Discount: " + result1);
|
||||||
|
|
||||||
|
Double result2 = DiscountStrategyFactory.getStrategy("2").discount(100.00);
|
||||||
|
System.out.println("60% Discount: " + result2);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
使用spring
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.discount;
|
||||||
|
|
||||||
|
import org.springframework.stereotype.Component;
|
||||||
|
|
||||||
|
@Component
|
||||||
|
public class Discount90Strategy implements DiscountStrategy {
|
||||||
|
@Override
|
||||||
|
public Double discount(Double price) {
|
||||||
|
return price * 0.9;
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public String mark() {
|
||||||
|
return "1";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.discount;
|
||||||
|
|
||||||
|
import org.springframework.stereotype.Component;
|
||||||
|
|
||||||
|
@Component
|
||||||
|
public class Discount80Strategy implements DiscountStrategy {
|
||||||
|
@Override
|
||||||
|
public Double discount( Double price) {
|
||||||
|
return price * 0.8;
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public String mark() {
|
||||||
|
return "2";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.discount;
|
||||||
|
|
||||||
|
import org.springframework.stereotype.Component;
|
||||||
|
|
||||||
|
@Component
|
||||||
|
public class Discount50Strategy implements DiscountStrategy {
|
||||||
|
@Override
|
||||||
|
public Double discount(Double price) {
|
||||||
|
return price * 0.5;
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public String mark() {
|
||||||
|
return "3";
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.discount;
|
||||||
|
|
||||||
|
import org.springframework.beans.factory.InitializingBean;
|
||||||
|
import org.springframework.beans.factory.annotation.Autowired;
|
||||||
|
import org.springframework.context.ApplicationContext;
|
||||||
|
import org.springframework.stereotype.Component;
|
||||||
|
|
||||||
|
import java.util.HashMap;
|
||||||
|
import java.util.Map;
|
||||||
|
|
||||||
|
@Component
|
||||||
|
public class DiscountFactory implements InitializingBean {
|
||||||
|
@Autowired
|
||||||
|
private ApplicationContext context;
|
||||||
|
|
||||||
|
|
||||||
|
private final Map<String, DiscountStrategy> discountStrategies = new HashMap<>();
|
||||||
|
|
||||||
|
public DiscountStrategy chooseStrategy(String type) {
|
||||||
|
return discountStrategies.get(type);
|
||||||
|
}
|
||||||
|
|
||||||
|
@Override
|
||||||
|
public void afterPropertiesSet() throws Exception {
|
||||||
|
Map<String, DiscountStrategy> beans = context.getBeansOfType(DiscountStrategy.class);
|
||||||
|
beans.forEach((k, v) -> discountStrategies.put(v.mark(), v));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example.discount;
|
||||||
|
|
||||||
|
public interface DiscountStrategy {
|
||||||
|
Double discount(Double price);
|
||||||
|
|
||||||
|
String mark();
|
||||||
|
}
|
||||||
|
```
|
||||||
|
|
||||||
|
```java
|
||||||
|
package org.example;
|
||||||
|
|
||||||
|
import org.example.config.AppConfig;
|
||||||
|
import org.example.discount.DiscountFactory;
|
||||||
|
import org.example.discount.DiscountStrategy;
|
||||||
|
import lombok.extern.slf4j.Slf4j;
|
||||||
|
|
||||||
|
import org.junit.Test;
|
||||||
|
import org.junit.runner.RunWith;
|
||||||
|
import org.springframework.beans.factory.annotation.Autowired;
|
||||||
|
import org.springframework.boot.test.context.SpringBootTest;
|
||||||
|
|
||||||
|
import org.springframework.test.context.junit4.SpringRunner;
|
||||||
|
|
||||||
|
@RunWith(SpringRunner.class) // Add this annotation
|
||||||
|
@SpringBootTest(classes = AppConfig.class)
|
||||||
|
@Slf4j
|
||||||
|
public class DiscountTest {
|
||||||
|
@Autowired
|
||||||
|
private DiscountFactory discountFactory;
|
||||||
|
|
||||||
|
@Test
|
||||||
|
public void test() {
|
||||||
|
DiscountStrategy strategy = discountFactory.chooseStrategy("2");
|
||||||
|
Double result = strategy.discount(1000.0);
|
||||||
|
log.info(String.valueOf(result));
|
||||||
|
}
|
||||||
|
}
|
||||||
|
|
||||||
|
```
|
||||||
|
|
||||||
|
```xml
|
||||||
|
<?xml version="1.0" encoding="UTF-8"?>
|
||||||
|
<project xmlns="http://maven.apache.org/POM/4.0.0"
|
||||||
|
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
|
||||||
|
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
|
||||||
|
<modelVersion>4.0.0</modelVersion>
|
||||||
|
|
||||||
|
<parent>
|
||||||
|
<groupId>org.springframework.boot</groupId>
|
||||||
|
<artifactId>spring-boot-starter-parent</artifactId>
|
||||||
|
<version>3.2.5</version>
|
||||||
|
<relativePath/>
|
||||||
|
</parent>
|
||||||
|
|
||||||
|
<groupId>org.example</groupId>
|
||||||
|
<artifactId>learn_juc</artifactId>
|
||||||
|
<version>1.0-SNAPSHOT</version>
|
||||||
|
|
||||||
|
<properties>
|
||||||
|
<java.version>17</java.version>
|
||||||
|
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
|
||||||
|
</properties>
|
||||||
|
|
||||||
|
<dependencies>
|
||||||
|
<dependency>
|
||||||
|
<groupId>org.springframework.boot</groupId>
|
||||||
|
<artifactId>spring-boot-starter</artifactId>
|
||||||
|
</dependency>
|
||||||
|
<dependency>
|
||||||
|
<groupId>org.slf4j</groupId>
|
||||||
|
<artifactId>slf4j-api</artifactId>
|
||||||
|
</dependency>
|
||||||
|
<dependency>
|
||||||
|
<groupId>ch.qos.logback</groupId>
|
||||||
|
<artifactId>logback-classic</artifactId>
|
||||||
|
</dependency>
|
||||||
|
|
||||||
|
<dependency>
|
||||||
|
<groupId>org.projectlombok</groupId>
|
||||||
|
<artifactId>lombok</artifactId>
|
||||||
|
<optional>true</optional>
|
||||||
|
</dependency>
|
||||||
|
|
||||||
|
<dependency>
|
||||||
|
<groupId>org.springframework.boot</groupId>
|
||||||
|
<artifactId>spring-boot-starter-test</artifactId>
|
||||||
|
<scope>test</scope>
|
||||||
|
</dependency>
|
||||||
|
<dependency>
|
||||||
|
<groupId>junit</groupId>
|
||||||
|
<artifactId>junit</artifactId>
|
||||||
|
<scope>test</scope>
|
||||||
|
</dependency>
|
||||||
|
</dependencies>
|
||||||
|
|
||||||
|
<build>
|
||||||
|
<plugins>
|
||||||
|
<plugin>
|
||||||
|
<groupId>org.springframework.boot</groupId>
|
||||||
|
<artifactId>spring-boot-maven-plugin</artifactId>
|
||||||
|
<configuration>
|
||||||
|
<excludes>
|
||||||
|
<exclude>
|
||||||
|
<groupId>org.projectlombok</groupId>
|
||||||
|
<artifactId>lombok</artifactId>
|
||||||
|
</exclude>
|
||||||
|
</excludes>
|
||||||
|
</configuration>
|
||||||
|
</plugin>
|
||||||
|
</plugins>
|
||||||
|
</build>
|
||||||
|
|
||||||
|
</project>
|
||||||
|
```
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
# 优点
|
||||||
|
|
||||||
|
提高灵活性和可维护性:通过将算法的实现与使用分离开来,当需要修改或添加新算法时,只需定义新的策略类并将其传递给环境类即可,无需修改环境类代码。
|
||||||
|
|
||||||
|
提高代码复用性:算法被封装在独立的策略类中,使得这些算法可以被多个不同的客户(环境类)复用。
|
||||||
|
|
||||||
|
动态切换算法:允许在程序运行时根据需要动态地改变和选择算法,从而实现不同的功能和行为,使程序更灵活。
|
||||||
|
|
||||||
|
算法实现与使用分离使代码更清晰:客户端代码仅需关注如何选择和使用不同的算法,而不必关心算法的具体实现细节,使代码更简洁、易于理解和扩展。
|
||||||
|
|
||||||
|
避免大量条件语句:当需要根据不同条件选择不同算法时,策略模式可以避免使用复杂的 if-else 或 switch 语句,使代码结构更清晰,更易于维护。
|
||||||
@@ -1,7 +1,7 @@
|
|||||||
import { type CollectionEntry, getCollection } from "astro:content";
|
import { type CollectionEntry, getCollection } from "astro:content";
|
||||||
import I18nKey from "@i18n/i18nKey";
|
import I18nKey from "@i18n/i18nKey";
|
||||||
import { i18n } from "@i18n/translation";
|
import { i18n } from "@i18n/translation";
|
||||||
import { getCategoryUrl } from "@utils/url-utils.ts";
|
import { getCategoryUrl, parseCategoryHierarchy, getCategoryAncestors } from "@utils/url-utils.ts";
|
||||||
|
|
||||||
// // Retrieve posts and sort them by publication date
|
// // Retrieve posts and sort them by publication date
|
||||||
async function getRawSortedPosts() {
|
async function getRawSortedPosts() {
|
||||||
@@ -74,41 +74,87 @@ export async function getTagList(): Promise<Tag[]> {
|
|||||||
|
|
||||||
export type Category = {
|
export type Category = {
|
||||||
name: string;
|
name: string;
|
||||||
|
fullName: string; // 完整的层级路径
|
||||||
count: number;
|
count: number;
|
||||||
url: string;
|
url: string;
|
||||||
|
level: number; // 层级深度,0为顶级
|
||||||
|
parent: string | null; // 父分类名称
|
||||||
|
children: Category[]; // 子分类
|
||||||
};
|
};
|
||||||
|
|
||||||
export async function getCategoryList(): Promise<Category[]> {
|
export async function getCategoryList(): Promise<Category[]> {
|
||||||
const allBlogPosts = await getCollection<"posts">("posts", ({ data }) => {
|
const allBlogPosts = await getCollection<"posts">("posts", ({ data }) => {
|
||||||
return import.meta.env.PROD ? data.draft !== true : true;
|
return import.meta.env.PROD ? data.draft !== true : true;
|
||||||
});
|
});
|
||||||
const count: { [key: string]: number } = {};
|
|
||||||
allBlogPosts.map((post: { data: { category: string | null } }) => {
|
const directCategoryCount: { [key: string]: number } = {}; // 直接分类计数
|
||||||
|
const totalCategoryCount: { [key: string]: number } = {}; // 包含子分类的总计数
|
||||||
|
const allCategories = new Set<string>();
|
||||||
|
|
||||||
|
// 收集所有分类
|
||||||
|
allBlogPosts.forEach((post: { data: { category: string | null } }) => {
|
||||||
if (!post.data.category) {
|
if (!post.data.category) {
|
||||||
const ucKey = i18n(I18nKey.uncategorized);
|
const ucKey = i18n(I18nKey.uncategorized);
|
||||||
count[ucKey] = count[ucKey] ? count[ucKey] + 1 : 1;
|
directCategoryCount[ucKey] = (directCategoryCount[ucKey] || 0) + 1;
|
||||||
|
totalCategoryCount[ucKey] = (totalCategoryCount[ucKey] || 0) + 1;
|
||||||
|
allCategories.add(ucKey);
|
||||||
return;
|
return;
|
||||||
}
|
}
|
||||||
|
|
||||||
const categoryName =
|
const categoryName = typeof post.data.category === "string"
|
||||||
typeof post.data.category === "string"
|
? post.data.category.trim()
|
||||||
? post.data.category.trim()
|
: String(post.data.category).trim();
|
||||||
: String(post.data.category).trim();
|
|
||||||
|
|
||||||
count[categoryName] = count[categoryName] ? count[categoryName] + 1 : 1;
|
// 直接分类计数
|
||||||
|
directCategoryCount[categoryName] = (directCategoryCount[categoryName] || 0) + 1;
|
||||||
|
allCategories.add(categoryName);
|
||||||
|
|
||||||
|
// 为所有祖先分类增加总计数
|
||||||
|
const ancestors = getCategoryAncestors(categoryName);
|
||||||
|
ancestors.forEach(ancestor => {
|
||||||
|
totalCategoryCount[ancestor] = (totalCategoryCount[ancestor] || 0) + 1;
|
||||||
|
allCategories.add(ancestor);
|
||||||
|
});
|
||||||
});
|
});
|
||||||
|
|
||||||
const lst = Object.keys(count).sort((a, b) => {
|
// 构建分类树
|
||||||
|
const categoryMap = new Map<string, Category>();
|
||||||
|
const rootCategories: Category[] = [];
|
||||||
|
|
||||||
|
// 按层级深度排序,确保父分类先创建
|
||||||
|
const sortedCategories = Array.from(allCategories).sort((a, b) => {
|
||||||
|
const aDepth = parseCategoryHierarchy(a).length;
|
||||||
|
const bDepth = parseCategoryHierarchy(b).length;
|
||||||
|
if (aDepth !== bDepth) return aDepth - bDepth;
|
||||||
return a.toLowerCase().localeCompare(b.toLowerCase());
|
return a.toLowerCase().localeCompare(b.toLowerCase());
|
||||||
});
|
});
|
||||||
|
|
||||||
const ret: Category[] = [];
|
sortedCategories.forEach(categoryName => {
|
||||||
for (const c of lst) {
|
const hierarchy = parseCategoryHierarchy(categoryName);
|
||||||
ret.push({
|
const level = hierarchy.length - 1;
|
||||||
name: c,
|
const displayName = hierarchy[hierarchy.length - 1];
|
||||||
count: count[c],
|
const parentFullName = hierarchy.length > 1
|
||||||
url: getCategoryUrl(c),
|
? hierarchy.slice(0, -1).join(' > ')
|
||||||
});
|
: null;
|
||||||
}
|
|
||||||
return ret;
|
const category: Category = {
|
||||||
|
name: displayName,
|
||||||
|
fullName: categoryName,
|
||||||
|
count: totalCategoryCount[categoryName] || 0, // 使用总计数
|
||||||
|
url: getCategoryUrl(categoryName),
|
||||||
|
level,
|
||||||
|
parent: parentFullName,
|
||||||
|
children: []
|
||||||
|
};
|
||||||
|
|
||||||
|
categoryMap.set(categoryName, category);
|
||||||
|
|
||||||
|
if (parentFullName && categoryMap.has(parentFullName)) {
|
||||||
|
categoryMap.get(parentFullName)!.children.push(category);
|
||||||
|
} else {
|
||||||
|
rootCategories.push(category);
|
||||||
|
}
|
||||||
|
});
|
||||||
|
|
||||||
|
return rootCategories;
|
||||||
}
|
}
|
||||||
|
|||||||
@@ -31,6 +31,35 @@ export function getCategoryUrl(category: string | null): string {
|
|||||||
return url(`/archive/?category=${encodeURIComponent(category.trim())}`);
|
return url(`/archive/?category=${encodeURIComponent(category.trim())}`);
|
||||||
}
|
}
|
||||||
|
|
||||||
|
// 解析分类层级结构
|
||||||
|
export function parseCategoryHierarchy(category: string): string[] {
|
||||||
|
if (!category || category.trim() === "") return [];
|
||||||
|
// 支持使用 "/" 或 " > " 作为分隔符
|
||||||
|
const separators = [' > ', '/'];
|
||||||
|
for (const sep of separators) {
|
||||||
|
if (category.includes(sep)) {
|
||||||
|
return category.split(sep).map(c => c.trim()).filter(c => c.length > 0);
|
||||||
|
}
|
||||||
|
}
|
||||||
|
return [category.trim()];
|
||||||
|
}
|
||||||
|
|
||||||
|
// 获取父分类
|
||||||
|
export function getParentCategory(category: string): string | null {
|
||||||
|
const hierarchy = parseCategoryHierarchy(category);
|
||||||
|
return hierarchy.length > 1 ? hierarchy.slice(0, -1).join(' > ') : null;
|
||||||
|
}
|
||||||
|
|
||||||
|
// 获取所有祖先分类(包括自己)
|
||||||
|
export function getCategoryAncestors(category: string): string[] {
|
||||||
|
const hierarchy = parseCategoryHierarchy(category);
|
||||||
|
const ancestors: string[] = [];
|
||||||
|
for (let i = 1; i <= hierarchy.length; i++) {
|
||||||
|
ancestors.push(hierarchy.slice(0, i).join(' > '));
|
||||||
|
}
|
||||||
|
return ancestors;
|
||||||
|
}
|
||||||
|
|
||||||
export function getDir(path: string): string {
|
export function getDir(path: string): string {
|
||||||
const lastSlashIndex = path.lastIndexOf("/");
|
const lastSlashIndex = path.lastIndexOf("/");
|
||||||
if (lastSlashIndex < 0) {
|
if (lastSlashIndex < 0) {
|
||||||
|
|||||||
Reference in New Issue
Block a user