解决深分页问题
This commit is contained in:
BIN
public/api/i/2025/09/09/xh9385-1.webp
Normal file
BIN
public/api/i/2025/09/09/xh9385-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 22 KiB |
BIN
public/api/i/2025/09/09/xmphei-1.webp
Normal file
BIN
public/api/i/2025/09/09/xmphei-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 21 KiB |
BIN
public/api/i/2025/09/09/xn0e7q-1.webp
Normal file
BIN
public/api/i/2025/09/09/xn0e7q-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 17 KiB |
BIN
public/api/i/2025/09/09/xp3bld-1.webp
Normal file
BIN
public/api/i/2025/09/09/xp3bld-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 46 KiB |
81
src/content/posts/中间件/MySQL/MySQL中如何解决深度分页问题.md
Normal file
81
src/content/posts/中间件/MySQL/MySQL中如何解决深度分页问题.md
Normal file
@@ -0,0 +1,81 @@
|
||||
---
|
||||
title: MySQL中如何解决深度分页问题
|
||||
published: 2025-09-09
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['MySQL', '分页','深度分页']
|
||||
category: '中间件 > MySQL'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# MySQL中如何解决深度分页问题
|
||||
|
||||
|
||||

|
||||
## 问题描述
|
||||
|
||||
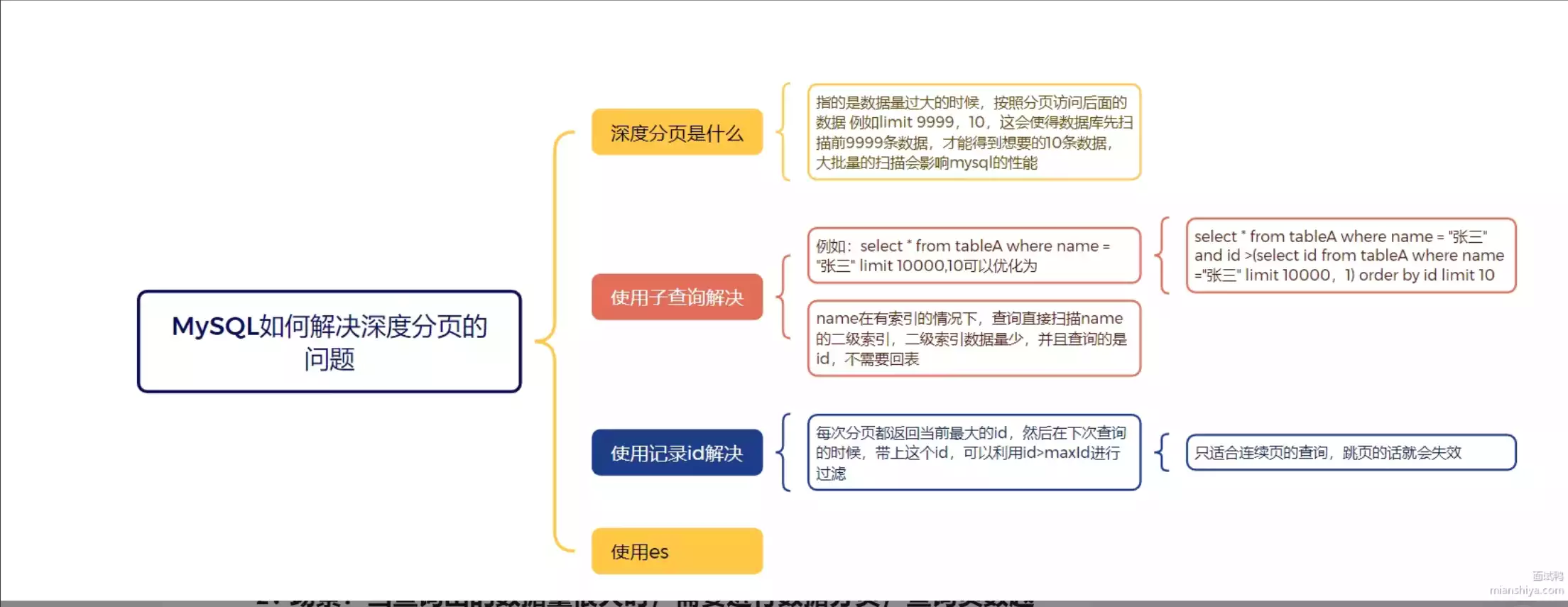
深度分页,指的是当数据量很大的时候,按照分页访问后面的数据,例如 `limit 9999990,10` 这会使得数据库要扫描前面的9999990条数据,才能得到最终的10条数据,大批量的扫描数据会增加数据库的负载,影响性能。
|
||||
|
||||
|
||||
## 三种优化方式
|
||||
### 记录id
|
||||
每次分页都返回当前的最大id,然后下次查询的时候,带上这个id,就能利用id > maxid过滤了。
|
||||
这种查询适合 连续查询的情况,如果跳页的话就不生效了。
|
||||
|
||||
普通分页的痛点:
|
||||
```sql
|
||||
SELECT * FROM article ORDER BY id LIMIT 10 OFFSET 100000;
|
||||
```
|
||||
MySQL 需要先扫描并跳过 前 100000 行,然后再返回后 10 行。(这里说下底层原因)
|
||||
|
||||
OFFSET 越大,性能越差。
|
||||
|
||||
我们每次查询时带上 上一次返回的最大 id,下一页就只要取 id > last_id 的记录。
|
||||
|
||||
不依赖 OFFSET,直接利用索引顺序扫描。
|
||||
|
||||
```sql
|
||||
select * from products limit 0,10; -- 第一页
|
||||
select * from products where id > 10 limit 10; -- 第二页
|
||||
select * from products where id > 20 limit 10; -- 第三页
|
||||
select * from products where id > 30 limit 10; -- 第四页
|
||||
```
|
||||
|
||||
### 子查询
|
||||
|
||||
这里其实和记录id的优化方式是一样的,只不过这里用的是子查询。理论上我们应该先去查询到上一页的最大id,然后再查询下一页的数据。
|
||||
|
||||
```sql
|
||||
SELECT * from products where id > (
|
||||
SELECT id from products order by created_at desc limit 199999,1) order by created_at desc limit 10;
|
||||
```
|
||||
这里我们给表的created_at建索引,可以利用created_at的二级索引进行扫描,然后利用id > 上一次查询的最大id进行过滤,最后再利用created_at的二级索引进行排序,最后再利用limit进行分页。
|
||||

|
||||
|
||||
子查询只读索引列(最好覆盖:筛选列 + 排序列 + id),IO 最小化。
|
||||
外层 JOIN 回表范围仅为一页大小(如 20 条),成本可控。
|
||||
|
||||
|
||||
相较于原来的
|
||||
```sql
|
||||
SELECT * FROM products order by created_at desc limit 200000,10;
|
||||
|
||||
```
|
||||
这个虽然可以利用created_at的二级索引进行扫描,但是它需要对每条记录进行一次回表操作,还要丢弃掉前200000条记录,性能较差。
|
||||
|
||||

|
||||
|
||||
|
||||
### join方法
|
||||
|
||||
```sql
|
||||
SELECT p.* FROM products p INNER JOIN (
|
||||
SELECT id FROM products ORDER BY created_at DESC limit 10 OFFSET 200000 ) AS page_results on p.id = page_results.id order by p.created_at desc;
|
||||
|
||||
```
|
||||
|
||||
这个和上面的子查询方式是一样的,只不过这里用的是join。
|
||||
|
||||
|
||||
### 使用es
|
||||
直接上elasticsearch,利用它本身分页的特性,进行优化。
|
||||
10
src/content/posts/中间件/MySQL/MySQL事务的两阶段提交是什么.md
Normal file
10
src/content/posts/中间件/MySQL/MySQL事务的两阶段提交是什么.md
Normal file
@@ -0,0 +1,10 @@
|
||||
---
|
||||
title: MySQL事务的两阶段提交是什么
|
||||
published: 2025-09-08
|
||||
description: ''
|
||||
image: ''
|
||||
tags: []
|
||||
category: ''
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
Reference in New Issue
Block a user