xxx
This commit is contained in:
BIN
public/api/i/2025/09/15/119ff4d-1.webp
Normal file
BIN
public/api/i/2025/09/15/119ff4d-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 16 KiB |
BIN
public/api/i/2025/09/15/12al42k-1.webp
Normal file
BIN
public/api/i/2025/09/15/12al42k-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 25 KiB |
BIN
public/api/i/2025/09/15/ucp5bt-1.webp
Normal file
BIN
public/api/i/2025/09/15/ucp5bt-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 40 KiB |
48
src/content/posts/Java/JUC/ConcurrentHashMap1.7和1.8的区别.md
Normal file
48
src/content/posts/Java/JUC/ConcurrentHashMap1.7和1.8的区别.md
Normal file
@@ -0,0 +1,48 @@
|
|||||||
|
---
|
||||||
|
title: ConcurrentHashMap1.7和1.8的区别
|
||||||
|
published: 2025-09-15
|
||||||
|
description: ''
|
||||||
|
image: ''
|
||||||
|
tags: [Java,ConcurrentHashMap]
|
||||||
|
category: 'Java'
|
||||||
|
draft: false
|
||||||
|
lang: ''
|
||||||
|
---
|
||||||
|
|
||||||
|
# JDK1.7
|
||||||
|
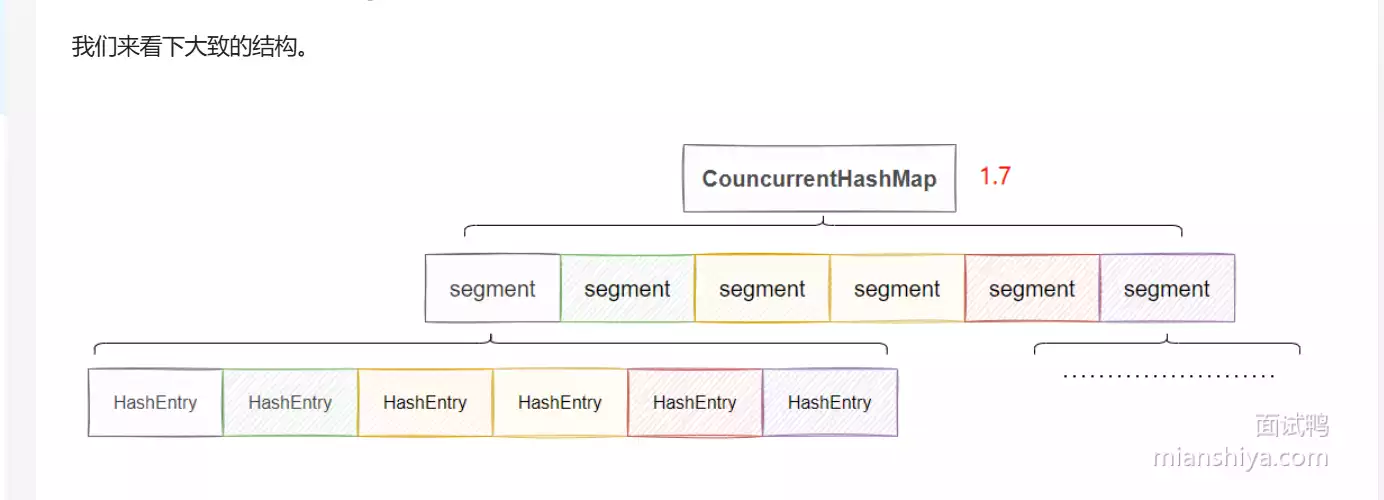
ConcurrentHashMap用的是分段锁,每个Segment是独立的,可以并发访问不同的Segment,默认是16个Segment,所以最多有16个线程可以并发执行。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
先通过key的hash判断得到Segment数组的下标,将这个Segment上锁,然后再次通过key的hash得到Segment里面HashEntry数组的下标。可以这么理解:每个Segment数组存放的就是一个单独的HashMap
|
||||||
|
|
||||||
|
缺点是Segment数组一旦初始化了之后就不会扩容,只有HashEntry数组会扩容,这就导致并发度过于死板
|
||||||
|
|
||||||
|
# JDK1.8
|
||||||
|
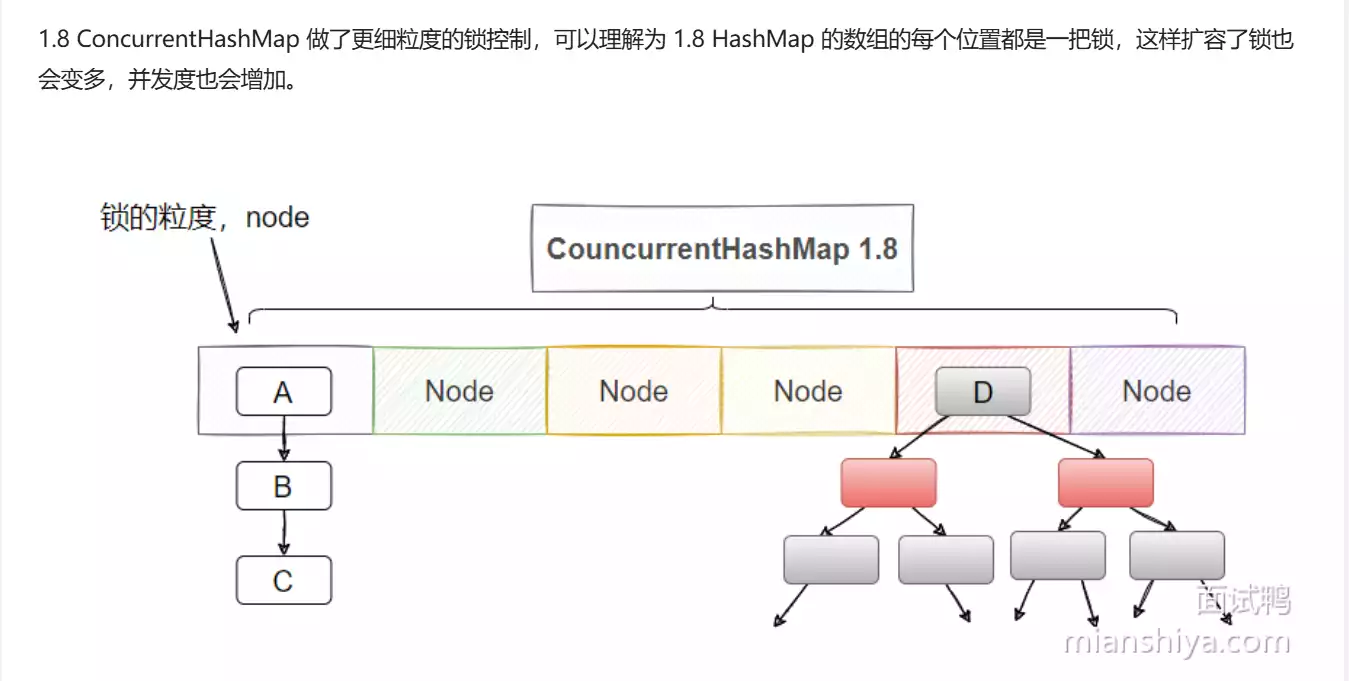
移除了分段锁,锁的粒度更加细化,锁只在链表或者红黑树**节点级别**上进行。通过CAS进行插入操作,只有在更新链表或者红黑树的时候才使用`synchronized`,并且只锁住链表或者树的头节点,进一步减少了锁的竞争,并发度大大增加。
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
1.8版本的ConcurrentHashMap也不借助ReentrantLock了,直接用synchronized。
|
||||||
|
|
||||||
|
当塞入一个值的时候,先计算key的hash后的下标,如果计算到的下标还没有Node,那么就通过CAS塞入新的Node,如果已经有node,就通过synchronized给这个node上锁,这样别的线程就无法访问这个node和它之后的所有节点了。
|
||||||
|
然后判断key是不是相等,相等就直接替换value,反之新增一个node。
|
||||||
|
|
||||||
|
# 扩容上面的区别
|
||||||
|
JDK1.7的扩容:
|
||||||
|
- 基于Segment: ConcurrentHashMap是由多个Segment组成的,每个Segment中包含一个HashMap,当某个Segment内的HashMap达到扩容阈值的时候,单独为该Segment进行扩容,不会影响到其他Segment
|
||||||
|
- 扩容过程: 每个Segment维护自己的负载因子,当Segment中的元素数量超过阈值的时候,这个Segment的HashMap会扩容,整体的ConcurrentHashMap并不是一次性全部扩容。
|
||||||
|
|
||||||
|
JDK1.8的扩容:
|
||||||
|
- 全局扩容: ConcurrentHashMap取消了Segment,变成了一个全局的数组(类似于HashMap)。因此当ConcurrentHashMap中任意位置的元素超过阈值的时候,整个ConcurrentHashMap的数组都会被扩容。
|
||||||
|
|
||||||
|
- 基于CAS扩容: 扩容的时候,ConcurrentHashMap采用了类似HashMap的方式。通过CAS确保线程安全,避免锁住整个数组。扩容的时候,多个线程可以同时帮助完成扩容操作。
|
||||||
|
|
||||||
|
- 渐进性扩容: JDK1.8的ConcurrentHashMap引入了渐进式扩容机制,
|
||||||
|
|
||||||
|
|
||||||
|
# size逻辑区别
|
||||||
|
1.7 是尝试,调用size方法的时候不加锁,三次结果一样那说明没有线程竞争,如果不一样,就加锁计算。
|
||||||
|
|
||||||
|
1.8的话,是直接计算返回结果,用的是LongAdder完成的累加。
|
||||||
@@ -4,7 +4,7 @@ published: 2025-08-08
|
|||||||
description: 深入理解Spring容器的核心接口BeanFactory与特殊工厂Bean——FactoryBean的区别、使用场景与最佳实践
|
description: 深入理解Spring容器的核心接口BeanFactory与特殊工厂Bean——FactoryBean的区别、使用场景与最佳实践
|
||||||
image: ''
|
image: ''
|
||||||
tags: [Java, Spring, IoC, DI, BeanFactory, FactoryBean]
|
tags: [Java, Spring, IoC, DI, BeanFactory, FactoryBean]
|
||||||
category: 'JAVA > Spring'
|
category: 'Java > Spring'
|
||||||
draft: false
|
draft: false
|
||||||
lang: zh-CN
|
lang: zh-CN
|
||||||
---
|
---
|
||||||
|
|||||||
@@ -8,6 +8,10 @@ category: '中间件 > Redis'
|
|||||||
draft: false
|
draft: false
|
||||||
lang: ''
|
lang: ''
|
||||||
---
|
---
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
|
|
||||||
Redis中的 big key指一个内存空间占用比较大的键,它有什么危害?
|
Redis中的 big key指一个内存空间占用比较大的键,它有什么危害?
|
||||||
- 内存分布不均,集群模式下,不同slot分配到不同实例中,如果大key被映射到同一个实例,那么分布不均,查询效率也会受到影响。
|
- 内存分布不均,集群模式下,不同slot分配到不同实例中,如果大key被映射到同一个实例,那么分布不均,查询效率也会受到影响。
|
||||||
- Redis单线程执行命令,操作大Key的时候耗时比较长,会导致Redis出现其他命令 阻塞的问题。
|
- Redis单线程执行命令,操作大Key的时候耗时比较长,会导致Redis出现其他命令 阻塞的问题。
|
||||||
|
|||||||
Reference in New Issue
Block a user