new
This commit is contained in:
BIN
public/api/i/2025/09/10/k90qnk-1.webp
Normal file
BIN
public/api/i/2025/09/10/k90qnk-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 45 KiB |
@@ -9,3 +9,18 @@ draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
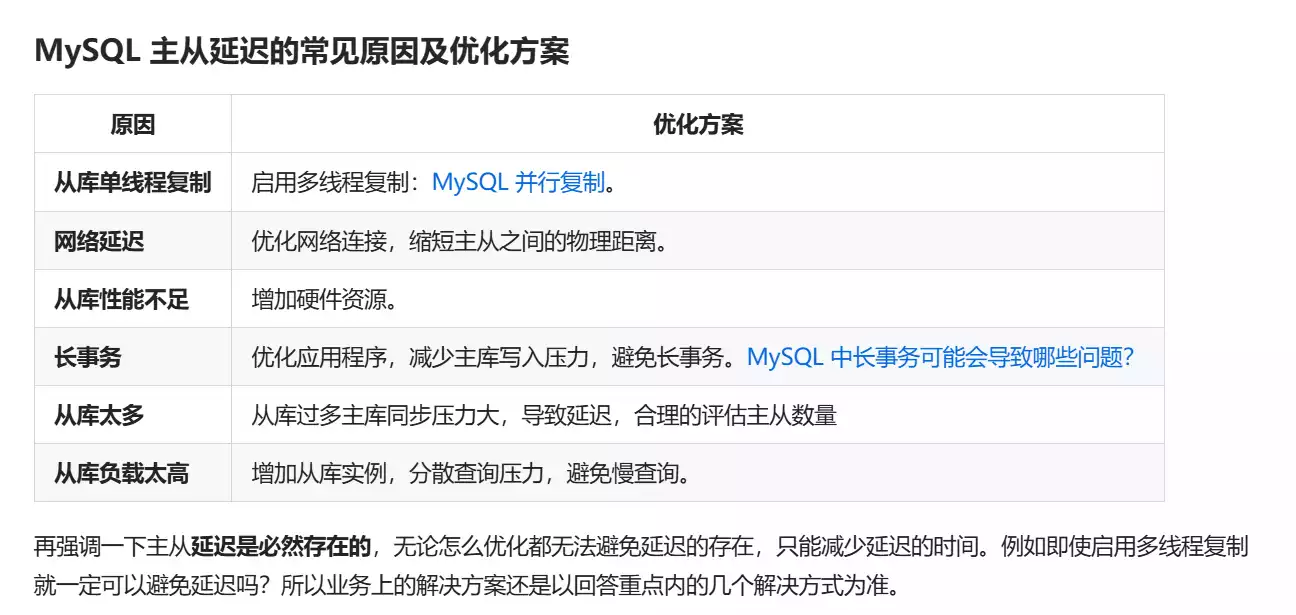
# 如何处理MySQL的主从同步延迟
|
||||
|
||||
当我们开启主从同步以后,这种延迟就是必然存在的,不论怎么优化都是没办法避免延迟的存在的,只能说去减少延迟的时间。
|
||||
|
||||
常见的解决方案:
|
||||
- 二次查询。如果说从库查不到数据,就去主库查一遍,用API封装这个逻辑就行,当作兜底策略。不过这样等于读的压力又转移到主库上去了,如果有人故意查询不存在的记录,那就会把查询的读请求都打到主库上了。
|
||||
- 强制把写之后立马读的操作转移到主库上(写后读主策略)。 写请求完成后,后续一段时间或者同一会话内的查询强制路由到主库,或者在从库追上指定位点前都读主。这个方法虽然简单可靠,能保证用户操作后的可见性,但是会增加主库的读压力,削弱负载分摊。
|
||||
- 关键业务读写都走主库。像我们用户注册这种,就可以读写主库,就不会出现说登录报用户不存在的问题了,这种访问量的频率也不高。
|
||||
- 使用缓存。 主库写入一行同步到缓存里面,这样查询的时候可以先查缓存,避免延迟,但是这样又有数据一致性问题了,我们就要去考虑数据库和缓存的数据一致性问题了。
|
||||
|
||||
|
||||
还有可能是 **主库的配置高,从库的配置低**,这样的话,也会导致主从同步延迟,我们可以提高从库的配置。
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user