xxx
This commit is contained in:
BIN
public/api/i/2025/09/12/12boul3-1.webp
Normal file
BIN
public/api/i/2025/09/12/12boul3-1.webp
Normal file
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 119 KiB |
17
src/content/posts/中间件/Redis/RedisString底层.md
Normal file
17
src/content/posts/中间件/Redis/RedisString底层.md
Normal file
@@ -0,0 +1,17 @@
|
||||
---
|
||||
title: RedisString底层
|
||||
published: 2025-09-12
|
||||
description: ' RedisString底层 '
|
||||
image: ''
|
||||
tags: ['Redis', '中间件','RedisString底层']
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# RedisString底层
|
||||
|
||||
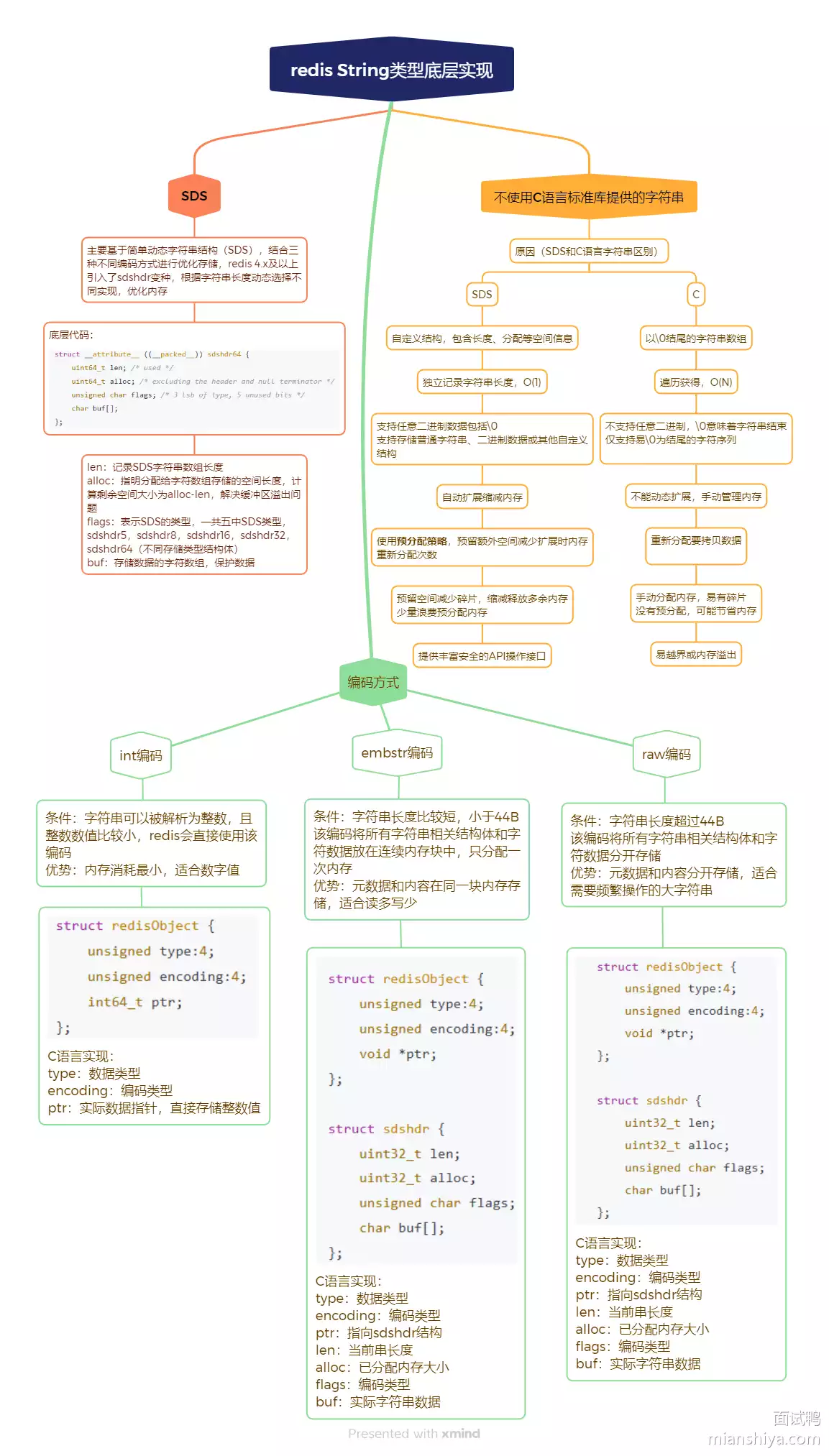
RedisString底层是使用SDS(Simple Dynamic String)实现的,SDS是一个动态字符串,可以动态扩容。
|
||||
|
||||
|
||||
|
||||
32
src/content/posts/中间件/Redis/Redis缓存击穿缓存穿透缓存雪崩.md
Normal file
32
src/content/posts/中间件/Redis/Redis缓存击穿缓存穿透缓存雪崩.md
Normal file
@@ -0,0 +1,32 @@
|
||||
---
|
||||
title: Redis缓存击穿缓存穿透缓存雪崩
|
||||
published: 2025-09-12
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['Redis', '中间件','缓存击穿']
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
|
||||
# 缓存击穿
|
||||
缓存击穿说的是,某个热点数据在缓存中失效,导致大量请求打到数据库。这时候由于瞬间的高并发,可能导致数据库崩溃。
|
||||
## 解决方案
|
||||
- 分布式锁: 在获取缓存的时候,使用分布式锁,保证只有一个请求获取到缓存。这样的话,就不会因为热点数据过期失效,而让请求都打到数据库里了。
|
||||
- 热点数据永不过期
|
||||
|
||||
# 缓存穿透
|
||||
缓存穿透说的是,某个热点数据在缓存中不存在,导致大量请求打到数据库。这时候由于瞬间的高并发,可能导致数据库崩溃。
|
||||
|
||||
## 解决方案
|
||||
- 使用布隆过滤器,布隆过滤器对于不存在的数据是能100%判断的,所以用布隆过滤器能过滤掉不存在的请求。
|
||||
- 对查询的空结果进行缓存,第二次访问直接返回空值。
|
||||
|
||||
# 缓存雪崩
|
||||
|
||||
多个缓存数据在同一时刻过期,导致大量请求同时访问数据库,导致数据库崩溃。
|
||||
|
||||
## 解决方案
|
||||
- 采用随机时间过期策略,避免多个数据同时过期。
|
||||
- 使用双缓存策略,把数据存储在两层缓存里面,减少数据库的直接请求。
|
||||
|
||||
636
src/content/posts/中间件/Redis/缓存与数据库一致性问题.md
Normal file
636
src/content/posts/中间件/Redis/缓存与数据库一致性问题.md
Normal file
@@ -0,0 +1,636 @@
|
||||
---
|
||||
title: 缓存与数据库一致性问题
|
||||
published: 2025-09-12
|
||||
description: ''
|
||||
image: ''
|
||||
tags: ['Redis', '中间件','缓存与数据库一致性']
|
||||
category: '中间件 > Redis'
|
||||
draft: false
|
||||
lang: ''
|
||||
---
|
||||
# 缓存与数据库一致性
|
||||
|
||||
缓存和数据库一致性是说在使用缓存的情况下,保证缓存中的数据和数据库中数据一致的问题。
|
||||
|
||||
**“先写缓存再写数据库”、“先写数据库再写缓存”、“先删除缓存再写数据库”这三种策略确实存在较大的数据不一致风险,因此通常不建议直接使用**,特别是在高并发、分布式系统中。
|
||||
|
||||
|
||||
|
||||
# 问题
|
||||
|
||||
## 先写缓存再写数据库
|
||||
|
||||
- **策略:先写缓存 (Redis),再写数据库 (MySQL)**
|
||||
|
||||
**图示场景:** 有两个写请求 A 和 B,同时尝试更新票务余票。初始余票是 17,经过两个用户的扣减,**期望**最终余票是 15。
|
||||
|
||||
**并发执行时序 (按图中箭头顺序):**
|
||||
|
||||
1. 写请求 A:
|
||||
|
||||
更新 Redis 缓存
|
||||
|
||||
,将余票设为 16。
|
||||
|
||||
- 此时 Redis: 16,MySQL: 17
|
||||
|
||||
2. 写请求 B:
|
||||
|
||||
更新 Redis 缓存
|
||||
|
||||
,将余票设为 15。
|
||||
|
||||
- 此时 Redis: 15,MySQL: 17 (请求 B 覆盖了请求 A 在 Redis 里的值)
|
||||
|
||||
3. 写请求 B:
|
||||
|
||||
更新 MySQL 数据库
|
||||
|
||||
,将余票设为 15。
|
||||
|
||||
- 此时 Redis: 15,MySQL: 15 (到这里,Redis 和 MySQL 暂时一致)
|
||||
|
||||
4. 写请求 A:
|
||||
|
||||
更新 MySQL 数据库
|
||||
|
||||
,将余票设为 16。
|
||||
|
||||
- 此时 Redis: 15,MySQL: 16 (请求 A 的数据库更新发生在 B 之后,覆盖了 B 在数据库里的值)
|
||||
|
||||
## 先写数据库再写缓存
|
||||
|
||||
**策略:先写数据库 (MySQL),再写缓存 (Redis)**
|
||||
|
||||
**图示场景:** 同样是两个写请求 A 和 B,尝试更新余票,初始 17,期望最终是 15。
|
||||
|
||||
**并发执行时序 (按图中箭头顺序):**
|
||||
|
||||
1. 写请求 A:
|
||||
|
||||
更新 MySQL 数据库
|
||||
|
||||
,将余票设为 16。
|
||||
|
||||
- 此时 Redis: 17 (假设初始),MySQL: 16
|
||||
|
||||
2. 写请求 B:
|
||||
|
||||
更新 MySQL 数据库
|
||||
|
||||
,将余票设为 15。
|
||||
|
||||
- 此时 Redis: 17,MySQL: 15 (数据库被 B 更新为最终期望值)
|
||||
|
||||
3. 写请求 B:
|
||||
|
||||
更新 Redis 缓存
|
||||
|
||||
,将余票设为 15。
|
||||
|
||||
- 此时 Redis: 15,MySQL: 15 (暂时一致,且是正确期望值)
|
||||
|
||||
4. 写请求 A:
|
||||
|
||||
更新 Redis 缓存
|
||||
|
||||
,将余票设为 16。
|
||||
|
||||
- 此时 Redis: 16,MySQL: 15 (请求 A 的缓存更新发生在 B 的缓存更新之后,覆盖了 B 在缓存里的值)
|
||||
|
||||
**最终结果:**
|
||||
|
||||
- Redis 缓存中的余票是 **16**。
|
||||
- MySQL 数据库中的余票是 **15**。
|
||||
|
||||
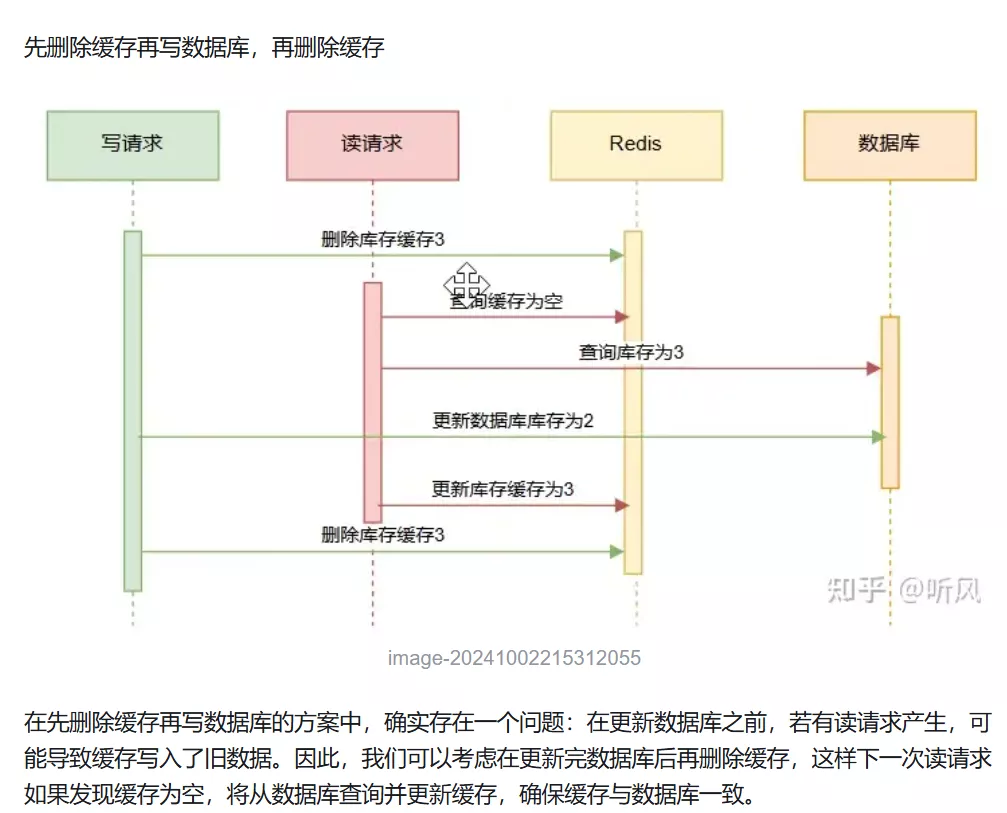
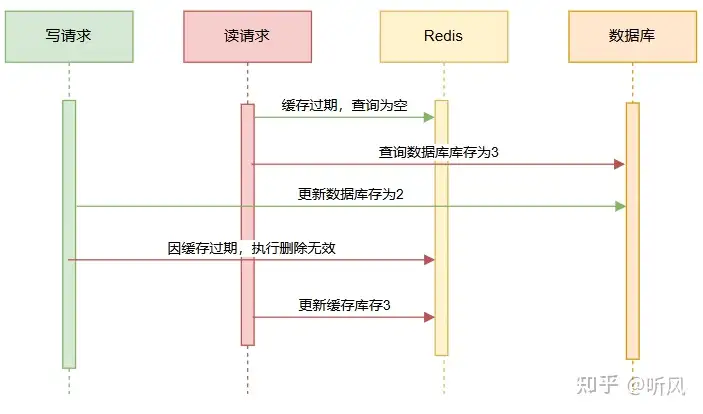
## 先删除缓存,再写数据库
|
||||
|
||||
**策略:先删除缓存 (Redis),再写数据库 (MySQL)**
|
||||
|
||||
**图示场景:** 这次涉及一个写请求和一个读请求并发执行。初始时,假设 Redis 和 MySQL 中的余票都是 16。写请求想将余票更新为 15。
|
||||
|
||||
**并发执行时序 (按图中箭头顺序):**
|
||||
|
||||
1. 写请求:
|
||||
|
||||
删除 Redis 缓存
|
||||
|
||||
,删除车站余票的 key (假定初始值是 16,所以图中箭头描述为“删除车站余票缓存 16”,但这只表示删的是这个key对应的旧数据)。
|
||||
|
||||
- 此时 Redis: 空,MySQL: 16
|
||||
|
||||
2. 读请求:
|
||||
|
||||
在写请求
|
||||
|
||||
还未来得及更新数据库之前
|
||||
|
||||
,并发地发起
|
||||
|
||||
读操作
|
||||
|
||||
。读请求先
|
||||
|
||||
查询缓存
|
||||
|
||||
,发现
|
||||
|
||||
缓存为空
|
||||
|
||||
。
|
||||
|
||||
- 此时 Redis: 空,MySQL: 16
|
||||
|
||||
3. 读请求:
|
||||
|
||||
缓存未命中,读请求转向
|
||||
|
||||
查询 MySQL 数据库
|
||||
|
||||
。此时写请求尚未完成数据库更新,所以从数据库中读到的是
|
||||
|
||||
旧数据 16
|
||||
|
||||
。
|
||||
|
||||
- 此时 Redis: 空,MySQL: 16,读请求获取到数据 16
|
||||
|
||||
4. 写请求:
|
||||
|
||||
更新 MySQL 数据库
|
||||
|
||||
,将余票设为 15。
|
||||
|
||||
- 此时 Redis: 空,MySQL: 15
|
||||
|
||||
5. 读请求:
|
||||
|
||||
将从数据库读到的
|
||||
|
||||
旧数据 16 回写到 Redis 缓存
|
||||
|
||||
中。
|
||||
|
||||
- 此时 Redis: 16,MySQL: 15
|
||||
|
||||
**最终结果:**
|
||||
|
||||
- Redis 缓存中的余票是 **16** (旧值)。
|
||||
- MySQL 数据库中的余票是 **15** (新值)。
|
||||
|
||||
# 解决方案
|
||||
|
||||
根据业务场景选择下面的缓存一致性方案:
|
||||
|
||||
- **缓存双删**:如果公司现有消息队列中间件,可以考虑使用该方案,反之则不需要考虑。
|
||||
- **先写数据库再删缓存**:这种方案从实时性以及技术实现复杂度来说都比较不错,推荐大家使用这种方案。
|
||||
- **Binlog 异步更新缓存**:如果希望实现最终一致性以及数据多中心模式,该方案无疑是最合适的。
|
||||
|
||||
## 缓存双删
|
||||
|
||||
|
||||
|
||||
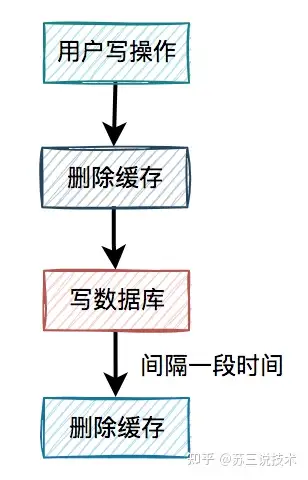
**先删除缓存 -> 写数据库 -> 延迟一段时间 -> 再次删除缓存**
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
|
||||
## 先写入数据库,再删除缓存
|
||||
|
||||
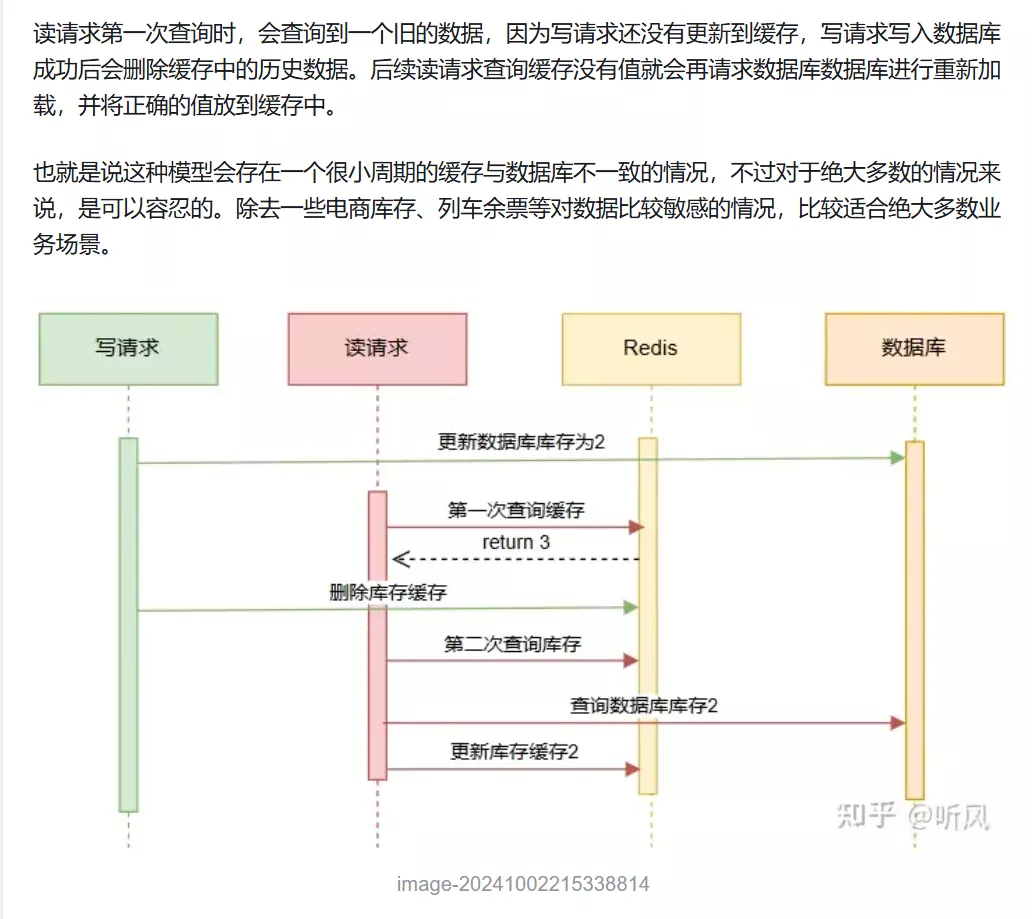
**"先写 DB 再删除缓存"是一种常用的缓存一致性解决方案,也被称为“写回策略”或“Write-Through 策略”。**
|
||||
|
||||
1. 当应用程序进行写操作时,首先将数据写入数据库。
|
||||
2. 然后,立即删除相应的缓存数据(或使缓存数据失效)。
|
||||
3. 当下一个读取请求到达时,会发现缓存中没有相应的数据,于是从数据库中读取最新的数据,并将其存储在缓存中。
|
||||
|
||||
这种策略的优势在于它保证了数据库和缓存之间的一致性。如果应用程序写入数据库并删除缓存,下一个读取操作将从数据库中获取最新数据,从而避免了数据不一致的情况。
|
||||
|
||||
|
||||
|
||||
当然,这种模型也不是完全没问题,如果说恰巧读缓存失效了,就会出现这种情况。
|
||||
|
||||
当缓存过期(可能是缓存正常过期也可能是 Redis 内存满了触发清理策略)条件满足,同时读请求的回写缓存 Redis 的执行周期在数据库删除之前,那么就有可能触发缓存数据库不一致问题。
|
||||
|
||||
上面说的两种情况,缺一不可,不过能同时满足这两种情况概率极低,低到可以忽略这种情况。
|
||||
|
||||
|
||||
|
||||
这种模型会存在一个很小周期的缓存与数据库**不一致**的情况,不过对于绝大多数的情况来说,是可以容忍的。除去一些电商库存、列车余票等对数据比较敏感的情况,比较适合绝大多数业务场景。
|
||||
|
||||
# AI问答,一些思考
|
||||
|
||||
# 数据库缓存方案:先删后写与双删
|
||||
|
||||
[(99 封私信 / 80 条消息) 『延迟双删』和『先修改数据库,再删除缓存』哪个方案更好? - 知乎](https://www.zhihu.com/question/556172201)
|
||||
|
||||
|
||||
|
||||
### 🧑💻 User
|
||||
|
||||
所以先写数据库,再删缓存
|
||||
和缓存双删
|
||||
都是企业中正常使用的方案?
|
||||
|
||||
---
|
||||
|
||||
### 🤖 Assistant
|
||||
|
||||
<details style="background-color: #f5f5f5; padding: 5px; border-radius: 10px; margin-bottom: 10px;">
|
||||
<summary>已深度思考</summary><hr>
|
||||
好的,用户现在在问关于数据库和缓存操作的两种常见方案:“先写数据库,再删缓存”和“缓存双删”是否都是企业中正常使用的方案。我需要先解释这两种方案,然后说明它们的适用场景和企业中的实际使用情况。<br><br>首先,我需要回忆一下这两种策略的基本概念。先写数据库再删缓存,是指在更新数据时,先更新数据库,然后删除缓存中的旧值,这样下次读取时会从数据库重新加载最新数据到缓存。而缓存双删,是在更新数据库前后各删除一次缓存,防止在更新过程中有并发读请求导致缓存脏数据。<br><br>接下来,我需要解释为什么企业会使用这些方案。先写数据库再删缓存是比较常见的策略,因为它简单且在大多数情况下有效,尤其是在并发不高的场景。但可能存在的问题是,如果在删除缓存之前有读请求,会读取到旧的缓存值,不过这种情况概率较低,因为数据库更新通常比缓存操作快。<br><br>然后是缓存双删,这是为了解决先写后删可能存在的并发问题。比如,当更新数据库时,有一个读请求在数据库更新之后但缓存删除之前读取,这时候会从数据库拿到新数据,但可能在缓存删除前另一个写操作导致数据不一致。双删策略通过在更新前删一次,更新后等一段时间再删一次,来减少这种情况的发生。不过需要注意等待时间的设置,这取决于数据库的主从同步时间或其他延迟。<br><br>接下来要说明企业中是否正常使用。实际上,这两种方案都是常见的,但适用场景不同。先写后删更简单,适用于大部分场景;双删则在高并发或对一致性要求较高的场景中使用。同时,可能还要提到其他方案,比如写缓存(更新缓存而不是删除),但这种方式可能有一致性问题,需要结合其他机制。<br><br>最后,需要总结这两种方案都是企业常用的,但需要根据具体场景选择,并可能结合其他优化措施,比如延迟双删中的等待时间,或者使用消息队列来确保缓存删除成功。<br><br>现在需要按照用户要求的格式来组织回答:标题带emoji,解释部分要详细但易懂,可能用例子或类比,最后一个问题。<br><br>标题可能用“数据库与缓存更新策略:先写后删 vs 双删 🗄️🔄”这样的。<br><br>解释部分需要分点说明两种策略,它们的流程、优缺点、适用场景,以及企业中的实际应用情况。可能用一个例子,比如用户修改个人信息,先更新数据库再删缓存,或者双删的情况。<br><br>最后,问用户是否想了解更多细节,比如具体实现或其他缓存策略。<br>
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
数据库与缓存更新策略:先写后删 vs 双删 🗄️🔄
|
||||
|
||||
在企业级系统中,数据库(持久化存储)和缓存(高速临时存储)的协同工作是性能优化的核心。为了保证数据一致性(数据库和缓存中的数据同步),常见的两种策略是“先写数据库,再删缓存”和“缓存双删”,它们都是企业中**根据场景灵活选用**的方案,我们逐一拆解:
|
||||
|
||||
|
||||
### 1. 先写数据库,再删缓存:最基础的“保守派”
|
||||
|
||||
**流程**:当需要更新数据时,先完成数据库的写操作(确保持久化存储是最新的),然后删除缓存中对应的旧值。下次读取时,由于缓存缺失,系统会从数据库读取最新数据并重新写入缓存(即“缓存击穿”后的自动填充)。
|
||||
|
||||
**为什么企业用它?**
|
||||
|
||||
- **简单可靠**:逻辑清晰,只有两步操作(写库→删缓存),易于实现和维护。
|
||||
- **风险可控**:数据库是“数据源头”,优先保证数据库的正确性(即使缓存删除失败,最多缓存中暂时保留旧数据,下次读取会自动更新)。
|
||||
|
||||
**潜在问题**:
|
||||
如果在“写数据库”和“删缓存”之间,有一个读请求到达,此时缓存中的旧数据还未被删除,读请求会拿到旧值。但这种情况发生概率较低(数据库写操作通常比缓存操作快,时间窗口短),因此在**并发量不高或对一致性要求不是极端严格**的场景(如用户信息、商品详情)中,企业普遍采用此方案。
|
||||
|
||||
|
||||
### 2. 缓存双删:高并发下的“增强版”
|
||||
|
||||
**流程**:为了进一步降低“先写后删”中旧缓存被读取的概率,在更新数据库前后各删除一次缓存(故称“双删”):
|
||||
① **先删缓存**:删除旧缓存(防止读请求拿到旧值);
|
||||
② **写数据库**:更新数据库;
|
||||
③ **延迟后再删缓存**:等待一段时间(比如1-5秒,具体取决于数据库主从同步或业务延迟),再次删除缓存(防止在写数据库期间,有新的读请求将旧数据重新写入缓存)。
|
||||
|
||||
**为什么企业用它?**
|
||||
|
||||
- **提升一致性**:通过两次删除,大幅缩小“旧缓存被读取”的时间窗口,适用于**高并发场景**(如秒杀活动、高频更新的订单状态)。
|
||||
- **应对复杂延迟**:如果数据库是主从架构(写主库→同步到从库有延迟),或缓存写入存在异步操作,双删能更好地覆盖这些延迟带来的不一致风险。
|
||||
|
||||
**潜在问题**:
|
||||
需要额外处理“延迟删除”的逻辑(比如用定时任务或消息队列实现),增加了系统复杂度;延迟时间过长可能影响性能,过短可能无法覆盖所有延迟场景,需要根据业务经验调优。
|
||||
|
||||
|
||||
### 企业实际使用场景总结
|
||||
|
||||
- **先写后删**:是“默认方案”,适用于大多数业务(如用户个人信息、商品基础属性),简单高效,满足90%以上场景的一致性需求。
|
||||
- **双删策略**:作为“增强方案”,用于高并发、强一致性要求的场景(如库存、交易订单),通过牺牲一定复杂度换取更高的数据一致性。
|
||||
|
||||
|
||||
你更想深入了解哪一种策略的具体实现细节?比如“先写后删”如何处理缓存删除失败,或“双删”中延迟时间如何计算? 😊
|
||||
|
||||
---
|
||||
|
||||
### 🧑💻 User
|
||||
|
||||
问题是缓存双删,你删了缓存,在删除和写入之间有读请求,哪个请求还是会拿到旧数据啊,这时候还是会让缓存是旧数据,但是数据库里是新的(短暂的),当然最后缓存还是要被二次删除
|
||||
|
||||
---
|
||||
|
||||
### 🤖 Assistant
|
||||
|
||||
<details style="background-color: #f5f5f5; padding: 5px; border-radius: 10px; margin-bottom: 10px;">
|
||||
<summary>已深度思考</summary><hr>
|
||||
好的,用户现在在问缓存双删策略中的一个具体问题:在第一次删缓存之后,写数据库之前,如果有读请求进来,这时候读请求会从数据库读取旧数据并重新写入缓存,导致缓存里是旧数据,而数据库之后会被更新为新数据。这时候虽然最后会二次删除缓存,但中间可能存在短暂的不一致。我需要解释这个问题,并说明为什么双删策略仍然有效,或者如何处理这种情况。<br><br>首先,用户的问题核心是双删策略中的时间窗口问题,即在第一次删除缓存后,写数据库前,读请求可能重新填充旧数据到缓存。这时候需要分析这个时间窗口的长度,以及如何通过延迟二次删除来解决。<br><br>需要回顾双删的流程:第一次删缓存→写数据库→延迟后二次删缓存。用户提到的情况是在第一步删缓存后,写数据库前,有读请求,此时数据库还是旧数据(因为还没写),所以读请求会从数据库读旧数据,然后写入缓存。这时候缓存里是旧数据,之后数据库被更新为新数据,这时候缓存里的旧数据会存在,直到二次删除触发。<br><br>需要解释为什么这种情况的影响有限,或者如何通过调整延迟时间来覆盖这个窗口。比如,假设写数据库的时间是T1,读请求的时间是在T0(第一次删缓存后,写数据库前),那么读请求会把旧数据写入缓存,之后数据库在T1被更新。此时缓存中的旧数据会存在,直到二次删除在T1+延迟时间执行。这时候如果延迟时间足够长,覆盖了可能的读请求重新填充缓存的时间,那么二次删除就能清除这个旧缓存,下次读请求就会从数据库读取新数据。<br><br>另外,可能需要提到这种情况的概率较低,因为写数据库通常是一个相对较快的操作,时间窗口较短。或者企业中如何通过其他手段(如分布式锁、异步补偿)来进一步降低风险。<br><br>还要注意用户可能的深层需求:是否双删策略真的能解决一致性问题,或者是否有其他更优的方案。需要明确双删是权衡后的选择,并非完美,但在大多数高并发场景下足够用。<br><br>最后,保持解释清晰,用例子或时间线来帮助理解,然后以问题结束,引导用户进一步提问。<br>
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
缓存双删中的“旧数据回灌”问题:时间窗口与延迟删除的奥秘 🕒🔍
|
||||
|
||||
你观察得非常细致!缓存双删策略确实存在一个“短暂的时间窗口”,可能让旧数据暂时回到缓存中。我们通过具体时间线模拟这个过程,再分析为什么企业仍选择这种方案,以及如何降低风险:
|
||||
|
||||
|
||||
### 场景模拟:双删中的“旧数据回灌”
|
||||
|
||||
假设我们要更新一条用户的“账户余额”数据,流程如下(时间顺序):
|
||||
1️⃣ **第一次删缓存**(T0时刻):删除缓存中旧的“账户余额”(假设旧值是100元)。
|
||||
2️⃣ **读请求插入旧数据**(T1时刻,T0 < T1 < T2):此时数据库还未更新(仍是旧值100元),一个读请求到达→缓存缺失→从数据库读取旧值100元→重新写入缓存(缓存现在是100元)。
|
||||
3️⃣ **写数据库**(T2时刻):数据库更新为新值200元(完成持久化)。
|
||||
4️⃣ **第二次删缓存**(T3时刻,T3 = T2 + 延迟时间):等待一段时间后,再次删除缓存(此时缓存中的100元被删除)。
|
||||
|
||||
|
||||
### 为什么这种“短暂不一致”可以接受?
|
||||
|
||||
虽然T1到T3期间,缓存中是旧值(100元),数据库是新值(200元),但这种不一致的**持续时间极短**(仅T3 - T1),且企业通过以下方式降低影响:
|
||||
|
||||
#### 1. 延迟时间的“精准控制”
|
||||
|
||||
第二次删除的“延迟时间”(如1-5秒)是关键。它需要覆盖“数据库写操作的耗时 + 可能的读请求重新填充缓存的耗时”。例如:
|
||||
|
||||
- 假设数据库写操作耗时0.5秒,读请求从数据库读数据+写缓存耗时0.3秒,那么延迟时间设为1秒即可覆盖T2到T3的窗口,确保在第二次删除时,缓存中可能存在的旧数据被清除。
|
||||
|
||||
#### 2. 高并发下的“概率稀释”
|
||||
|
||||
在实际场景中,“读请求恰好出现在T0-T2窗口”的概率较低。因为:
|
||||
|
||||
- 写数据库操作通常是同步的(如事务提交),耗时极短(毫秒级);
|
||||
- 即使有读请求进入,它们大多是“分散”的,不会集中在这个微小的时间窗口内。
|
||||
|
||||
#### 3. 最终一致性的“兜底”
|
||||
|
||||
即使出现短暂不一致,第二次删除后,下一次读请求会从数据库读取最新值(200元)并重新填充缓存,最终保证缓存与数据库一致。
|
||||
|
||||
|
||||
### 企业如何进一步优化?
|
||||
|
||||
如果业务对一致性要求极高(如金融交易),企业可能会结合以下策略:
|
||||
|
||||
- **分布式锁**:在写操作期间,对关键数据加锁,阻止读请求在T0-T2窗口内重新填充缓存(但会牺牲部分性能);
|
||||
- **异步补偿**:通过日志监控缓存与数据库的差异,发现不一致时主动触发缓存更新;
|
||||
- **缓存版本号**:为缓存添加版本标识(如时间戳),读请求填充缓存时检查版本,旧版本数据直接丢弃。
|
||||
|
||||
|
||||
总结来说,双删策略的“旧数据回灌”是理论上存在的,但通过合理设置延迟时间、结合其他优化手段,企业可以将其影响控制在可接受范围内。它本质上是“性能与一致性”的权衡——用微小的短暂不一致,换取高并发下的整体高效。
|
||||
|
||||
|
||||
关于双删策略,你还想了解哪些细节?比如“如何计算具体的延迟时间”或“分布式锁如何与双删配合使用”? 😊
|
||||
|
||||
---
|
||||
|
||||
### 🧑💻 User
|
||||
|
||||
这不和先更新数据库,再删除缓存一样吗?
|
||||
|
||||
---
|
||||
|
||||
### 🤖 Assistant
|
||||
|
||||
<details style="background-color: #f5f5f5; padding: 5px; border-radius: 10px; margin-bottom: 10px;">
|
||||
<summary>已深度思考</summary><hr>
|
||||
好的,用户现在的问题是:“这不和先更新数据库,再删除缓存一样吗?”需要解释缓存双删和先写数据库再删缓存的区别,以及为什么两者不同。首先,我需要回顾之前的对话,用户已经了解了这两种策略,现在可能混淆了它们的差异。<br><br>首先,用户的疑问是双删和先写后删是否一样。需要明确两者的核心区别在于操作顺序和步骤数量。先写后删是两步:写库→删缓存;双删是三步:删缓存→写库→延迟删缓存。<br><br>接下来,需要解释为什么双删不是简单的先写后删的重复。要指出时间窗口的不同,以及双删如何针对先写后删的缺陷进行优化。比如,先写后删的问题是在写库和删缓存之间可能有读请求拿到旧缓存,而双删通过提前删缓存和延迟再删来缩小这个窗口。<br><br>然后,用具体的时间线对比两种策略,说明在同样的读请求干扰下,两种策略的表现差异。比如,先写后删中,读请求可能在写库之后、删缓存之前到达,导致缓存保留旧值;而双删中,第一次删缓存后,读请求可能在写库前重新填充旧值,但第二次删缓存会清除它。<br><br>还要强调双删的“延迟”步骤的作用,以及为什么这额外的步骤能提升一致性,尽管仍有短暂窗口,但比先写后删更优。<br><br>最后,总结两者的适用场景,让用户明白它们不是一样的,而是针对不同并发和一致性需求的解决方案。<br><br>需要保持解释清晰,用例子和时间线帮助理解,避免术语过于复杂。同时,按照系统提示的格式,标题要有emoji,解释部分分点,最后问用户想深入的问题。<br>
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
缓存双删 vs 先写后删:步骤差异与一致性提升的本质区别 🧩🔄
|
||||
|
||||
你的观察很敏锐!两者确实都涉及“写数据库”和“删缓存”,但核心差异在于**操作顺序、步骤数量**和**对“读请求干扰”的防御机制**。我们通过具体场景对比,就能清晰看到它们的不同。
|
||||
|
||||
|
||||
### 先写数据库,再删缓存:“被动防御”的基础策略
|
||||
|
||||
**流程**:写数据库(T1)→ 删缓存(T2)。
|
||||
**时间线示例**(假设要更新用户余额为200元):
|
||||
|
||||
- T0:数据库旧值100元,缓存旧值100元(初始状态)。
|
||||
- T1:写数据库完成(新值200元)。
|
||||
- T2:删除缓存(此时缓存被清空)。
|
||||
- **风险窗口**:若在T1到T2之间(写库后、删缓存前)有读请求:
|
||||
读请求发现缓存未删(仍为100元)→ 直接返回旧值(缓存旧值,数据库新值),导致不一致。
|
||||
|
||||
|
||||
### 缓存双删:“主动+延迟”的增强策略
|
||||
|
||||
**流程**:删缓存(T0)→ 写数据库(T1)→ 延迟后再删缓存(T2)。
|
||||
**时间线示例**(同样更新用户余额为200元):
|
||||
|
||||
- T0:第一次删缓存(缓存旧值100元被删除,缓存为空)。
|
||||
- T1:写数据库完成(新值200元)。
|
||||
- **风险窗口**:若在T0到T1之间(删缓存后、写库前)有读请求:
|
||||
读请求发现缓存为空→ 从数据库读旧值100元→ 重新写入缓存(缓存现在是100元)。
|
||||
- T2(延迟后):第二次删缓存(清除此时可能存在的旧值100元)。
|
||||
|
||||
|
||||
### 关键差异:风险窗口的“位置”与“处理方式”
|
||||
|
||||
| 策略 | 风险窗口位置 | 风险窗口内的读请求行为 | 最终一致性如何保证? |
|
||||
| -------- | ------------------------- | -------------------------------------- | ------------------------------------ |
|
||||
| 先写后删 | 写库后、删缓存前(T1-T2) | 读请求拿到缓存旧值(数据库已更新) | 下次读请求时缓存被删,重新加载新值 |
|
||||
| 缓存双删 | 删缓存后、写库前(T0-T1) | 读请求重新写入缓存旧值(数据库未更新) | 第二次删缓存清除旧值,下次读加载新值 |
|
||||
|
||||
|
||||
### 为什么双删不是“先写后删的重复”?
|
||||
|
||||
1. **风险窗口更小**:写数据库通常比删缓存耗时(如事务提交可能需要毫秒级),而“先删缓存”让风险窗口出现在“写库前”(此时数据库还是旧值),读请求即使回灌旧值,数据库本身未更新,后续第二次删缓存后,下次读请求会从已更新的数据库加载新值。
|
||||
2. **主动防御延迟**:双删通过“延迟第二次删除”覆盖了数据库写操作的耗时,确保即使有读请求在写库前回灌旧值,最终也会被清除。而先写后删没有这一步,风险窗口内的读请求可能长期保留旧缓存(直到下次自然失效)。
|
||||
|
||||
|
||||
### 总结:两者是“互补”而非“相同”
|
||||
|
||||
- 先写后删:简单、高效,适用于低并发或一致性要求不高的场景(风险窗口短,概率低)。
|
||||
- 缓存双删:通过“两次删除+延迟”主动缩小风险窗口,适用于高并发、一致性要求更高的场景(如库存、交易)。
|
||||
|
||||
|
||||
你更想了解哪种策略在具体代码中的实现细节?比如先写后删如何用代码处理“删缓存失败”,或双删的“延迟时间”如何用定时任务实现? 😊
|
||||
|
||||
---
|
||||
|
||||
### 🧑💻 User
|
||||
|
||||
奥我懂了,双删时候,风险窗口期间,数据库未更新,其实是不算不一致的对吧,就算请求B取数据库并且更新缓存,那个值也是那个时刻的正确数值。
|
||||
但是我有个问题,后面更新数据库后,这时候缓存如果被之前的请求更新为旧的数据,这时候不就是不一致了吗?这期间进来的请求拿到的不就是旧的值了吗?
|
||||
|
||||
---
|
||||
|
||||
### 🤖 Assistant
|
||||
|
||||
<details style="background-color: #f5f5f5; padding: 5px; border-radius: 10px; margin-bottom: 10px;">
|
||||
<summary>已深度思考</summary><hr>
|
||||
好的,用户现在的问题是关于缓存双删策略中的不一致情况。用户之前已经理解了双删的基本流程,现在进一步疑惑:当数据库更新后,如果缓存被之前的读请求填充了旧数据,这时候是否会导致不一致,以及后续请求是否会拿到旧值。<br><br>首先,我需要确认用户的问题核心:在双删的时间窗口中,读请求可能在数据库更新前读取旧数据并填充缓存,而当数据库更新后,这个缓存中的旧数据是否会导致不一致,以及如何解决。<br><br>接下来,我需要解释在数据库更新后,缓存中的旧数据确实会导致短暂的不一致,但双删的第二次删除会解决这个问题。需要详细说明时间线,让用户明确每个阶段的数据状态。<br><br>然后,用户可能想知道为什么这种不一致是短暂的,以及第二次删除的作用。需要强调延迟时间的重要性,确保在第二次删除时,旧数据被清除,后续请求会从数据库获取新值。<br><br>另外,用户可能隐含担心这种短暂不一致是否会影响业务,需要说明实际场景中这种情况的概率和持续时间都很低,以及企业如何通过优化手段(如调整延迟时间、监控)来进一步降低风险。<br><br>最后,保持回答的结构:标题、解释、总结问题,确保符合之前的格式要求,用易懂的语言和例子帮助用户理解。<br>
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
缓存双删中的“短暂不一致”与二次删除的关键作用 🕰️🔧
|
||||
|
||||
你完全抓住了问题的核心!这种情况下确实会出现“数据库已更新,但缓存仍存旧值”的短暂不一致,但双删策略的“第二次删除”正是为了解决这个问题。我们通过时间线拆解和具体例子,来彻底理清这个过程。
|
||||
|
||||
|
||||
### 时间线模拟:数据库更新后,缓存为何会有旧值?
|
||||
|
||||
假设要更新用户“账户余额”(旧值100元→新值200元),双删流程的时间线如下(关键节点标注):
|
||||
|
||||
| 时间点 | 操作/事件 | 数据库状态 | 缓存状态 |
|
||||
| ------ | ------------------------------ | ------------------- | ------------------------------------------------ |
|
||||
| T0 | 第一次删缓存(主动删除旧缓存) | 仍为100元(未更新) | 缓存被清空(无数据) |
|
||||
| T1 | 读请求A到达(在T0-T2之间) | 仍为100元(未更新) | 缓存空→读数据库取100元→写缓存(缓存现在是100元) |
|
||||
| T2 | 写数据库完成(更新为200元) | 变为200元(已更新) | 缓存仍为100元(旧值) |
|
||||
| T3 | 第二次删缓存(延迟后执行) | 200元(已更新) | 缓存中的100元被删除(缓存再次清空) |
|
||||
| T4 | 读请求B到达(T3之后) | 200元(已更新) | 缓存空→读数据库取200元→写缓存(缓存现在是200元) |
|
||||
|
||||
|
||||
### 为什么T2到T3期间会“不一致”?
|
||||
|
||||
在T2(数据库更新完成)到T3(第二次删缓存)的时间段内:
|
||||
|
||||
- 数据库:已存储最新值200元(正确);
|
||||
- 缓存:被读请求A在T1时刻填充了旧值100元(错误)。
|
||||
|
||||
此时,若有新的读请求在T2-T3之间到达,会直接读取缓存中的旧值100元,导致“缓存旧、数据库新”的不一致。
|
||||
|
||||
|
||||
### 但这种不一致为何是“短暂可控”的?
|
||||
|
||||
关键在**第二次删除(T3)**和**延迟时间的设计**:
|
||||
|
||||
#### 1. 第二次删除强制清空旧缓存
|
||||
|
||||
无论缓存中是否有旧值,T3时刻的二次删除会直接清除缓存中的100元。此时缓存变为空,后续读请求(如T4的读请求B)只能从数据库读取最新的200元,并重新填充缓存为正确值。
|
||||
|
||||
#### 2. 延迟时间覆盖“数据库写操作耗时”
|
||||
|
||||
T3 = T2 + 延迟时间(如1秒)。延迟时间需要足够长,确保:
|
||||
|
||||
- 数据库写操作(T0到T2)已完全完成;
|
||||
- 所有可能在T0-T2期间触发的读请求(如读请求A)都已完成缓存填充。
|
||||
|
||||
这样,第二次删除时,缓存中可能存在的旧值(100元)会被彻底清除,避免长期留存。
|
||||
|
||||
|
||||
### 极端情况:如果第二次删除失败了怎么办?
|
||||
|
||||
假设T3时刻二次删除因网络问题失败,缓存中的旧值100元未被清除,此时会发生什么?
|
||||
|
||||
- 后续读请求仍会读取到旧值,但这种情况属于“异常”,企业通常会通过以下方式兜底:
|
||||
- **缓存过期时间**:即使没有二次删除,缓存的TTL(如5分钟)会自动失效,最终强制从数据库加载新值;
|
||||
- **监控与补偿**:通过日志监控缓存与数据库的差异,发现不一致时手动或自动触发缓存更新。
|
||||
|
||||
|
||||
### 总结:双删的“不一致”是“阶段性的”,而非“永久性的”
|
||||
|
||||
虽然T2-T3期间可能出现“缓存旧、数据库新”的短暂不一致,但:
|
||||
|
||||
- 持续时间由延迟时间决定(通常仅几秒);
|
||||
- 第二次删除强制清除旧缓存,后续请求会自动加载新值;
|
||||
- 结合缓存过期时间,最终一致性得以保证。
|
||||
|
||||
|
||||
关于这种“短暂不一致”的业务影响,你还想了解哪些场景?比如“金融系统如何容忍这种短暂不一致”或“如何通过监控发现这类问题”? 😊
|
||||
|
||||
---
|
||||
|
||||
### 🧑💻 User
|
||||
|
||||
这个第二次删缓存的延迟是什么?能讲一下吗
|
||||
|
||||
---
|
||||
|
||||
### 🤖 Assistant
|
||||
|
||||
<details style="background-color: #f5f5f5; padding: 5px; border-radius: 10px; margin-bottom: 10px;">
|
||||
<summary>已深度思考</summary><hr>
|
||||
好的,用户现在问的是缓存双删中第二次删除的延迟是什么,需要详细解释。首先,我需要明确延迟的作用、如何确定延迟时间,以及实际应用中的例子。用户可能已经理解了双删的基本流程,但对延迟的具体作用和设置方法不太清楚,需要用易懂的方式解释。<br><br>首先,要解释延迟的定义:在写数据库完成后,等待一段时间再执行第二次删缓存的操作。然后,说明为什么需要这个延迟——覆盖数据库写操作的耗时,确保所有可能在风险窗口内的读请求已经完成缓存填充,这样第二次删除才能有效清除旧值。<br><br>接下来,需要具体说明延迟时间的确定方法。比如,要考虑数据库写操作的最大耗时,加上网络延迟、应用处理时间等。举个例子,假设写数据库平均耗时200ms,最大可能到500ms,那么延迟可以设置为1秒(500ms*2),确保所有可能的读请求已经完成。<br><br>然后,可以用时间线的例子来演示延迟的作用,比如没有延迟的话,第二次删除可能在数据库还没写完时就执行,导致无效;而有了延迟,确保数据库已经更新完成,此时删除缓存才能真正清除可能存在的旧值。<br><br>还要提到实际应用中如何实现这个延迟,比如使用定时任务、消息队列的延迟投递,或者简单的线程睡眠(但要注意分布式系统中的问题)。同时,需要指出延迟时间不是固定的,需要根据业务场景调整,比如高并发系统可能需要更长的延迟,而低并发可以缩短。<br><br>最后,总结延迟的核心目的是确保第二次删除的有效性,避免缓存中残留旧值,从而减少不一致的时间窗口。同时,保持回答的结构,符合之前的格式要求:标题带emoji,解释部分分点或举例,最后提一个问题引导用户继续提问。<br>
|
||||
</details>
|
||||
|
||||
|
||||
|
||||
缓存双删中“延迟时间”的作用与设计逻辑 ⏳🔍
|
||||
|
||||
你问到了双删策略的核心细节!这里的“延迟”不是随意等待,而是经过设计的“时间缓冲带”,它的存在直接决定了双删策略能否有效减少缓存与数据库的不一致。我们通过“为什么需要延迟”“如何确定延迟时长”“实际如何实现”三个维度来拆解。
|
||||
|
||||
|
||||
### 一、为什么需要“延迟时间”?——覆盖“风险窗口”的残留旧值
|
||||
|
||||
在双删流程中,第一次删缓存(T0)后,可能有读请求在“写数据库前”(T0-T1)从数据库读取旧值并重新写入缓存(比如读请求A在T0-T1期间将旧值100元写回缓存)。此时:
|
||||
|
||||
- 数据库会在T1时刻更新为新值200元;
|
||||
- 但缓存中已被读请求A写入了旧值100元(这是问题的根源)。
|
||||
|
||||
如果没有延迟,第二次删缓存(T2)会在写数据库(T1)完成后**立即执行**。但此时可能存在两种情况:
|
||||
|
||||
1. 读请求A的缓存写入操作(旧值100元)还未完成(网络延迟或线程调度延迟),导致第二次删除时缓存中还没有旧值,删除无效;
|
||||
2. 即使删除了旧值,若后续还有其他读请求在“写数据库完成后、第二次删除前”再次读取到旧值,仍会导致短暂不一致。
|
||||
|
||||
**延迟的作用**:让“第二次删除”等待足够长的时间,确保所有在“写数据库前”触发的读请求(如读请求A)已经完成缓存写入(旧值100元),此时再删除,就能彻底清除这些残留的旧缓存。
|
||||
|
||||
|
||||
### 二、如何确定“延迟时长”?——基于数据库写操作的耗时
|
||||
|
||||
延迟时间的核心依据是“数据库写操作的最大耗时”(包括事务提交、主从同步等)。具体计算逻辑如下:
|
||||
|
||||
#### 公式:延迟时间 ≈ 数据库写操作的最大耗时 × 2(或1.5~3倍)
|
||||
|
||||
- **数据库写操作耗时**:指从执行写命令(如`UPDATE user SET balance=200 WHERE id=1`)到数据库确认写入完成(如事务提交、主库同步到从库)的时间。例如,在MySQL中,写操作可能需要50ms~200ms(高并发时可能更长)。
|
||||
- **乘以倍数的原因**:覆盖网络延迟、应用服务器与数据库的通信耗时,以及可能的读请求处理延迟(如读请求A的线程可能因CPU调度延迟执行缓存写入)。
|
||||
|
||||
**举例**:
|
||||
假设数据库写操作的最大耗时是300ms(包括主从同步),那么延迟时间可以设置为500ms~1秒。这样,即使读请求A在写数据库完成后(T1)才完成缓存写入(旧值100元),第二次删除(T2=T1+500ms)也能在缓存写入完成后执行,确保旧值被清除。
|
||||
|
||||
|
||||
### 三、实际如何实现“延迟删除”?——技术方案与注意事项
|
||||
|
||||
在代码中实现“延迟删除”有以下常见方式:
|
||||
|
||||
#### 1. 线程睡眠(简单但局限)
|
||||
|
||||
在写数据库完成后,让当前线程休眠指定时间(如500ms),然后执行第二次删除。
|
||||
|
||||
```java
|
||||
// 伪代码示例
|
||||
public void updateUserBalance(Long userId, Integer newBalance) {
|
||||
// 第一次删缓存
|
||||
redis.del("user:balance:" + userId);
|
||||
|
||||
// 写数据库(假设耗时200ms)
|
||||
userMapper.updateBalance(userId, newBalance);
|
||||
|
||||
// 延迟500ms(覆盖写操作耗时+可能的读请求处理)
|
||||
Thread.sleep(500);
|
||||
|
||||
// 第二次删缓存
|
||||
redis.del("user:balance:" + userId);
|
||||
}
|
||||
```
|
||||
|
||||
**局限**:在分布式系统中,若多个实例同时更新同一数据,可能因线程休眠导致性能问题;且无法精准控制延迟时间(受JVM调度影响)。
|
||||
|
||||
|
||||
#### 2. 定时任务/延迟队列(更可靠)
|
||||
|
||||
将第二次删除操作提交到延迟队列(如RocketMQ的延迟消息、Redis的ZSET+定时扫描),由队列在指定时间后触发删除。
|
||||
|
||||
```java
|
||||
// 使用RocketMQ延迟消息示例
|
||||
Message message = new Message(
|
||||
"cacheDeleteTopic",
|
||||
"user:balance:" + userId, // 消息内容为缓存键
|
||||
("deleteCache:" + userId).getBytes()
|
||||
);
|
||||
message.setDelayTimeLevel(3); // 延迟10秒(具体级别根据MQ配置)
|
||||
producer.send(message);
|
||||
```
|
||||
|
||||
**优势**:解耦业务逻辑,避免阻塞主线程;支持分布式场景,延迟时间更精准。
|
||||
|
||||
|
||||
#### 3. 异步线程池(折衷方案)
|
||||
|
||||
通过线程池提交一个异步任务,任务中先休眠指定时间,再执行删除。
|
||||
|
||||
```java
|
||||
// 伪代码示例
|
||||
ExecutorService executor = Executors.newSingleThreadExecutor();
|
||||
executor.submit(() -> {
|
||||
try {
|
||||
Thread.sleep(500); // 延迟500ms
|
||||
redis.del("user:balance:" + userId);
|
||||
} catch (InterruptedException e) {
|
||||
Thread.currentThread().interrupt();
|
||||
}
|
||||
});
|
||||
```
|
||||
|
||||
|
||||
### 四、极端情况:延迟时间不够会怎样?
|
||||
|
||||
如果延迟时间过短(如小于数据库写操作耗时),可能出现:
|
||||
|
||||
- 第二次删除时,数据库写操作尚未完成,此时缓存中可能被读请求写入更早的旧值(数据库还未更新),导致删除无效;
|
||||
- 或者,读请求在“第二次删除后”才完成缓存写入(旧值),此时缓存中仍会残留旧值,需要等待缓存过期才能恢复一致。
|
||||
|
||||
|
||||
### 总结:延迟是双删策略的“时间保险栓”
|
||||
|
||||
延迟时间的设计本质是**用时间换一致性**——通过等待足够长的时间,确保所有可能干扰缓存的读请求已完成旧值写入,再通过第二次删除彻底清除这些旧值。它是双删策略中“主动防御”的关键一环。
|
||||
|
||||
|
||||
关于延迟实现的具体技术细节(比如如何用Redis的ZSET实现延迟队列),或者不同业务场景下延迟时间的经验值(如电商库存vs用户信息),你更想深入了解哪部分? 😊
|
||||
Reference in New Issue
Block a user